
If you’ve had even a passing glance at tech journalism over the past few months, you know the top buzzword for AI in 2025 is agentic. Agentic AI (according to many think pieces and press releases at least) is going to revolutionize industry. It’s going to streamline complex pipelines and maximize efficiency. It will make corporations smarter, better, faster, and for cheaper. What makes agentic AI so powerful? Agentic AI can take action. These models—equipped with language modules, external databases, and ‘chain of thought’ reasoning—are designed to set goals, make plans, and execute actions. As a result they can have real impact in the world.
But what about us?
2025 is not just the year of agentic AI but also the start of a second Trump administration. In the short time since the Nazi-salute-containing inauguration day, the administration has enacted a slew of executive orders impacting everything from prescription drug prices to offshore drilling. ICE agents are conducting raids in previously safe spaces like churches and hospitals and sweeping up US citizens in the process. Government employees are actively encouraged to snitch on their peers. Scientists are being silenced and their funding requests halted or even canceled. Combined with the legacy of the first Trump administration, we are currently facing an upheaval in our access to everything from healthcare to voting to clean energy.
Each of these efforts constricts the space around every one of us, making our possible set of actions smaller and smaller. Thinking of expressing an opinion on diversity at work? Be careful, your co-worked may report you. Want to attend a Spanish mass in Chicago? They’re canceled, for fear of raids. Need to look up a fact about climate change or Jan. 6 investigations? The government websites are gone.
The result (and intention) of these rules and actions are to create a learned helplessness in us—to reduce our own sense of agency. And in fact we see signs of it working. Voter turnout dipped by about 5 million people in 2024 compared to 2020. The Women’s March and other protests that mobilized hundreds of thousands after the first Trump inauguration dwindled to a much smaller trickle this year.
Even the simple act of social media activism has been constrained. The owners of the largest information sharing channels in the world sat as esteemed guests at the inauguration, and their actions within their companies suggest the invitation was a welcome one. X (formerly twitter) won’t be of much use unless the actions you want to take are to the right. Threads has always been clear that it is not interested in political content, preferring to support the brand-rot banter of social media interns at large corporations instead. And should you manage to actually get a useful and actionable post out, say about how women can access Plan C, onto Instagram or Facebook, it will be taken down before many people can see.

So it seems the same people who want to push AI agents on us in their tech also want desperately to remove our own agency in real life. Wouldn’t Instagram be a nicer place if all the pesky, politically-motivated humans just sat back and observed the (fake) actions of AI-generated social media accounts? Perhaps the writers of Wall-E had the most accurate take on the future: an Earth so covered in trash it is abandoned, but nobody really cares because they’re given a constant stream of personalized entertainment without having to lift a finger, or even make a decision. Leave the agency to the robots.
The truth is, it can actually be a lot more fun to be an observer than an agent. I know, because I spent much of my life not feeling like an agent at all. Perhaps because I grew up in a cornfield-filled suburb where nobody really did anything that mattered, I never expected I would either. And so I simply observed. I observed the physical world and human behavior and patterns of thought. And this turned me into a scientist. But even doing science can feel like not really doing anything. A lot of academic scientists joke about getting a “real job” some day.
But through a combination of events personal, professional, and political, my perspective began to change. When my dad died shortly before I finished my PhD I was confronted with the uncomfortable possibility that I was now the adult in the room. When the pandemic struck and global chaos abounded I realized that people in power are—terrifyingly—just like me. And when I published a book and eventually heard from young people that this book impacted them, sometimes to the point of changing their careers, I realized that I was already acting in the world. And so I decided to take on the identity of an agent more strongly.
And this is how I know that living as an agent is both essential and life-giving, and also an unbearable burden. With agency comes responsibility. If you have the power to change the world then why aren’t you? ‘Can’ quickly becomes ‘ought’. Even after deciding to shift my career towards climate change (an agentic move if I ever made one), I still wonder if I’m doing enough. Even when I became directly involved in political campaigning (including overcoming my millennial phone-phobia to make calls for the Harris campaign), there was always the sense that I could have, and should have, done more. If modern AI agents had to experience true agency, with the moral weight that is intrinsically tied to it, their chains of thought would snap under the pressure.
Counterintuitively, this moral weight can feel even more acute the more constrained your action space is. I don’t have billions of dollars to invest in clean energy and so instead I agonize over every decision to take a flight or use a disposable cup. There is a stifling sadness in these small actions. When those with power take action free from moral constraints, you can feel like an ant moving grains of sand in the shadow of a bulldozer. You still can act. In fact you must act, but will your tiny actions matter?
I think a lot about the phrase “May you live in interesting times”, wrongly claimed to be a Chinese curse. If it is a curse, it is only a curse for the agent. To an observer, interesting times are entertainment: think of all the gripping movies that have been written about past times of turmoil and will be written about the current one. To the agent, though, who is actively trying to write the story as they live in it, interesting times are a minefield of potential wrong decisions and wasted efforts. At the same they also present the very real possibility of impact.
When we think of the current moment we have to remember why so many people in power want to constrict our agency. It is obviously because our actions do matter. Uncertain times present many possible futures. We, individually and collectively, do have the power to set the course. If our efforts were like a child playing with a toy cellphone, pressing buttons that lead to no outcomes, there would be no reason to take them away. The game of finding your route to greatest impact has certainly gotten harder, with more hurdles and dead-ends added along the way. But all that means is that we need to be cleverer, more committed, and take more action. In short, we need 2025 to be the year not of agentic AI but of agentic humans, operating with the full moral urgency that comes with that term and that the moment demands.
With the hottest days in recorded history, oceans reaching 100°F, droughts, and wildfire air turning the sky orange, it takes little more than walking out your door to be reminded of the ongoing climate crisis we are experiencing. As an academic, you may understand why this is happening. You may also be frightened, angered, or depressed about it. But you may fall short of knowing all that you personally can do about it. If so, this article is for you.
The first step is to learn the basic mantra of tackling climate change: It’s happening. It’s us. We can fix it. That is: the world is undeniably warming, as a result of greenhouse gas emissions from human activity, and we have a variety of methods for reducing those emissions and adapting to the unavoidable changes.
And as you can guess, it’s incredibly important that you act. The effects are already here and already troubling. But there is a lot more and far worse damage on the horizon that we can prevent by acting now. Every fraction of a degree matters. Every ounce of avoided emissions helps. And many of the needed solutions have secondary benefits, like cleaner air and cheaper energy. To serious people, there is therefore no space for doomerism or complacency. An incredible amount of necessary change is already happening, driven by people like you who care about fixing this problem, and they need your help to do even more.
What an academic can do ranges from the universal—personal actions anyone can take as a consumer and citizen—to the specific—use of hard-won expertise to advance technology and practice. I will cover the full range here, but, fair warning, I am going to try to convince you to change what you work on.
No matter what options you choose, to make the most impact, you will have to be bold. You will need to do things that haven’t been done before—things that aren’t the norm, or part of the typical academic path. Things that some people who don’t understand the situation as well as you might even think are weird. But that’s ok, because doing research and discovering new knowledge is inherently about working on the edge of what is known and comfortable. If you can forge new paths in your research, you can forge new paths in your personal and professional life as well.
Unprecedented action is needed because we are facing unprecedented conditions. Imagine you were conducting a study in your field and saw these kind of outliers:


It would make you sit up and take notice.
For the past century or so, we have been conducting a large-scale experiment (that did not get IRB approval…) on our planet and our civilization, and the data are coming in with strong results. We are in a new era and a new world. The way systems functioned and how people behaved before this period of climate upheaval is not a relevant guide for how things should be done in this new era. We have to be different. You have to be different. As Alex Steffan, a writer who focuses on how to grapple with a rapidly evolving world in crisis, wrote “Being native to now demands finding insight, not just receiving it.”
In addition to being bold and creative, to have the most impact, you need to be a “force multiplier”. For every action you take, try to get 10 other actions out of it. This can be done by getting whole systems you have control over to change or by convincing other people to make the same changes you are making.
So what can you do from where you are now…
As an academic, there are levers you can pull that will help reduce emissions and change the expectations and standards in your field. Much of the tips provided here come from Anne Urai and her colleagues whose extensive efforts help academics, and (neuro)scientists in particular, act on the climate crisis. Check out their papers and videos for more information.
First, you have certain affordances due to your position within a university. Universities are large systems that can play important roles in their communities and even internationally. Working with (or putting pressure on) your university to take bold and necessary action is one way to be a force-multiplier. Resources that are particularly relevant on university campuses are campaigns to divest from fossil fuels, the work of your sustainability office (these can sometimes be hubs for greenwashing, but it is your job to make sure they are not by offering input), and activist organizations like Sunrise Movement.
Efforts to change university policies are also part of a general movement of people lobbying their employers for climate action under the notion that “every job is a climate job”. General resources for climate action at work include this Project Drawdown guide and the UK-based Work for Climate organization.
You can also do an accounting of the emissions that come from your research. Think about materials used, the energy needed for computing power, and the emissions that come from flying to conferences. To make changes in these areas, you may need to: petition companies to offer more sustainable products, ask your university about where the energy for computing clusters comes from, or lobby your academic societies to offer distributed conferences (either through several local hubs or remote virtual participation like neuromatch). MyGreenLab and the Laboratory Efficiency Assessment Framework may be good starting points. But in general, be creative. When you find lower carbon alternatives to things you use and do regularly, make sure to share your knowledge, like Anne has in her publications for neuroscientists. This makes you a force multiplier.
Also consider what you teach. The causes of, effects from, and solutions to the climate crisis touch nearly every topic taught at a university. Teaching the physical science behind climate change is just as important as explaining the psychological tendencies that prevent action or the economic incentives needed for change. Try developing a new course on “Climate Change and X” for your department (for example, I teach Machine Learning for Climate Change as part of the Data Science major at NYU). Or at least see where in your existing lectures a connection to climate change and its solutions can be made. Not only does this open the eyes of students to how their interests connect to this global problem, it also normalizes talking about it and may encourage them to focus their career on it.
Professors, scientists, and academics are usually considered respected members of the community and therefore communicating from a place of authority can also be a useful option. Writing op-eds, appearing on podcasts, or helping provide input for policy efforts are ways academics can contribute to the conversation. Research on how to communicate on climate has provided many tips. In general, this communication can be particularly effective for targeted audiences, for example when commenting on how green efforts on your campus will be beneficial to the local community. Many scientists already engage in various forms of outreach, and including discussion of the climate crisis in these activities can be an easy way to get others talking. Scientists can even consider joining Scientist Rebellion to participate in coordinated action and activism. Getting the word out and normalizing the idea of taking climate action can be a force multiplier (for example, I’m force multiplying right now 🙂).
But you can also change what you do
An academic’s identity can be very tightly wound up with their area of expertise. To suggest that someone change what they work on can be shocking, offensive even. But what you do during your working hours determines in large part the impact you have on this world. If you want to increase your effort and expand your impact, pivoting your research to a climate-relevant topic is a great choice.
This pivot will admittedly be easier for some areas of expertise than others, but you may be surprised by the overlap in skills and knowledge that you have and what is needed for some specific corner of the climate crisis response. As mentioned above, it’s difficult to find a university department that has no relevant connection to climate change, and forging new connections can be incredibly important as well.
I wrote previously about my change from pure neuroscientist to neuroscientist/remote-sensing-of-climate-impacts-scientist. Did I think when I got my PhD in computational neuroscience that I’d be analyzing satellite data as a professor or developing content for a course on computational climate science? Of course not. But entering this new field has been exhilarating and expansive. It also gives me clear purpose and a place to put my energy when the news has me frustrated or depressed. And it provides me the time and space to stay up-to-date on climate topics, which otherwise would be a job of its own.
As an academic (especially if you are a tenured one), you have an uncommon degree of freedom in what you pursue. You also have a useful set of meta-skills—the ability to survey complicated literature, teach yourself new things, and manage multi-faceted research projects—that have value even outside of the domain you learned them in. This puts you in a rare position to explore and build and forge and test across a range of topic areas, and guide students into these areas as well. If you have the desire to make an impact on the climate crisis, don’t let the traditions of academia or a fear of what might come hold you back. Use the freedom and skills you have to do what you think is right.
But how do you figure out the best topic areas for you? If you’re a novice, The Climate Book is a decent place to start; it is a series of expert-authored essays that together provide a thorough lay of the land. Solutions-oriented frameworks like Project Drawdown and the UN Sustainable Development Goals can also point you to concrete areas that need attention. There are a host of podcasts to provide informal introductions to areas of interest and the people working on them; I prefer Catalyst and My Climate Journey.
I also highly recommend joining the Work on Climate Slack. This is a very large community of people either working on, or hoping to work on, climate change problems. It was started with the explicit goal of getting people from all backgrounds into climate work. It was a big influence on me as I made my transition and provided several concrete opportunities. The community of people working on climate is also incredibly welcoming. You can even join the #role-academics channel, which I created to help shepard academics through this process!
If you want to skill up with some online courses check out Climatematch Academy, Airminers (on carbon dioxide removal), Climate Change AI summer school, or a wide variety of options on websites like Coursera.
If you’re currently at a university, see what kind of climate work is already going on and who is doing it. Ask to attend meetings and seminars and see what kind of help you can offer or if your colleagues have any pointers to resources that are a good match for you. Some universities, like NYU, have established clusters of climate research and are even aiming to fund it more. Columbia University has an entire school dedicated to climate change, which accurately reflects the importance of the problem and its highly interdisciplinary nature. If your university doesn’t have any hubs of climate work, make one.
Remember, you don’t have to completely abandon your past work and go 100% on climate change (though please do if you’d like!). You can explore on the edges at first, dipping a toe into a new topic and see how it feels before taking a deeper plunge.
You may also conclude that you want to leave academia
For all its perks, academic work can sometimes feel like fighting with one hand tied behind your back; resources can be sparse and the chance to truly directly create something or make change can be hard to come by. If you want to leave academia, there are many resources that will help you make this switch.
First, know that you are in good company. Many academics have left their university to start or join companies working on climate solutions. Companies are usually happy to find smart and motivated people who want to work on their problems. So all you have to do is convey that interest and know how to market your skills.
Recent years have seen a healthy increase in acknowledgement of the fact people with PhDs end up in other jobs. Many resources exist to teach former academics how to identify their skills and passions outside of the ivory tower and get a job that suits them. Such resources include From PhD to Life and What You Can Be with a PhD and a variety of articles and conversations under the heading of “alt-ac”.
For resources specific to finding climate jobs, check out:
- Climatebase
- Terra.do
- Climate Jobs List
- Climate Tech List
- Climate People Recruiters
- Leafr freelancing
- Get a Job Starter Pack and Work on Climate
- How to get a data job in climate
And of course, the Work on Climate Slack and community are great places to network and learn more about what jobs are available and what they entail. See also this mega-list of resources for getting started in climate change work.
Thinking of starting your own company? Great! The world needs radically new ideas and ways of doing things as we undergo a massive climate transition. Climate Founder provides resources for entrepreneurs and Subak provides assistance and funding especially for non-profits. If you are still at a university, there may be a Tech Ventures office responsible for helping academics found start-ups. Funding agencies, like the NSF, also have programs to get scientist’s ideas into the real world. And you can check out the Scientist Founder Hub.
The past few years has seen the development of quite a healthy climate startup space. The money is flowing, the work exists and you are wanted there.
And don’t forget personal action
The most important personal action you can do is vote, and otherwise organize politically, perhaps even through targeted civil disobedience, to make sure that people who have the interest of future generations at heart get into power and make the right choices. US-focused political organizations include Citizen’s Climate Lobby, League of Conservation Voters, and People’s Climate Movement.
Other personal action is important too—without individual change we wouldn’t get collective change. Changes in consumption habits regarding meat alternatives and electric vehicles, for example, have allowed companies pioneering these climate-friendly options to thrive and sent a message to the makers of emissions-heavy products that they are no longer wanted.
Individual choices, while having a small but real impact on their own, are also important as force multipliers because of the conversations they start. When it comes up at dinner that I eat chicken and fish but tend to avoid dairy and beef, I can explain that this is due to the heavy carbon footprint of food that comes from cows. Similarly, when I decline an invitation to an international conference out of a desire to avoid too many flights, this may spur others to consider their own avenues for action as well. In Saving Us: A Climate Scientist’s Case for Hope and Healing in a Divided World, Katharine Hayhoe discusses how climate-friendly behavior can spread by seeing others do the same, and how conversations amongst people with shared values are the most effective.
Another personal action that matters is donating. This gives the people dedicating their life to important fights in courts and on the ground the resources they need to do their job well. My preferred organizations are: Clean Air Task Force, Earthjustice, Conservation International, Carbon Fund, and Environmental Defense Fund.
But just do it
Whatever of the above options resonates with you, just make sure you do it. Do it now and do more later. There is no reason to wait, and there truly is not time to. Action begets action. And action begets conversations that beget more action. Start the ball rolling now and reap the benefits that you sow.
If you have more resources you’d like to share, please post them in the comments or send me a message.
Hello all! I have recently started a new position as an Assistant Professor of Psychology and Data Science at New York University. You can find my lab website here: lindsay-lab.github.io
As you’ll notice on that site, I have three main intended areas of research: modeling the connection between attention and learning, validating the tools of systems neuroscience, and applying computer vision to climate change. The first area follows somewhat naturally from my PhD work, the second was born out some frustration during my postdoc, and the last …. well that seems like it’s really coming out of left field.
I hope to get back into a semi-regular habit of blogging again, and for my first blog post on my new lab website, I decided to explain exactly why my lab will focus on applications to climate change. I’m cross-posting that piece below, but you can find the original here.

“Artificial neural networks for psychology, neuroscience, and climate change”
That’s the tagline on the front page of this website. You may notice that one of those things is not like the others. In this inaugural lab blog post, I’m going to explain why.
At some point during the pandemic, I got really into reading about climate change. It may have been because I had my first kid, though that didn’t feel like the conscious reason. It may have been because Biden got elected and a lot of my other fears washed a way a bit to reveal this one big one. Or maybe it was just a desire to distract myself from one global disaster by focusing on another. Whatever the reason, while I’d had climate change on the backburner of my mind for many years (simmering away as the planet was…), at some point in early 2021, figuring out just how bad things were going to be became a priority.
And it was devastating and paralyzing.
Once I had really internalized it, I couldn’t stop thinking about the impact of my every move: the temperature I set my home to, every item of food I puchased, any time spent in a car. Simply existing—especially with a small child and all the cheap and disposable items that seem to inevitably come along with them—felt untenable. The Onion headline “Amount Of Water Man Just Used To Wash Dish To Be Prize Of Hand-To-Hand Combat Match In 2065” ran through my head more as prophecy than satire. My husband and I listened to a This American Life episode about a father who ruined his family by forcing them into further and further extremes of climate activism. We talked about how his actions were crazy, but also in a way, he was right, wasn’t he? I didn’t want to do that, but I had to do something.
So I focused on the personal side of things. I looked for the most impactful places to donate. I did a lot research into sustainable clothes and where to buy green household products. After being pescetarian for many years I decided to start eating chicken again but stop eating cheese because the CO2-to-protein conversion is better for poultry. This new awareness about better ways to live my everyday life offered some relief.
And then I just sort of realized…I can work on this. In addition to common lifestyle changes, I could use real skills of mine to do something. I didn’t have to just be a bystander, patronizing and supporting the businesses and organizations trying to make a change. I could put my energy into it and contribute directly myself—and wouldn’t that go a lot further in helping alleviate the guilt and concern, and make me feel like I can actually go on?
So I looked into what someone with my skillset could do. And I also looked into getting new skillsets. But switching topic area and skills at once is hard, so applying what I already knew a bit about—machine learning—to climate seemed the most reasonable way in. I joined a bunch of online communities (which I will collect in an upcoming blog post on working on climate), I took online courses, listened to podcasts, and found some chances to start doing climate data science.
Immersing yourself in an entirely new field—or fields really—as a 30-something year old is weird. You can feel like you don’t even know where to start. But it’s also totally fun. Especially with something like climate change work, which touches absolutely every aspect of everything about your life. I started to think about materials — what is everything around me made of and why? And how could it be done differently to make it all more doable for the longer term. I started to pay a lot of attention to shipping too—where were things coming from and how did they get here? On a jetski tour to the Statue of Liberty, I got distracted by the barges coming over the horizon. And weather! Clouds had so much more meaning after I learned about global wind and pressure patterns. Same for agriculture, energy, ecology, etc. The sense of empowerment that came from knowing more about how the world around me works was an unexpected benefit.
And it’s true that action is the antidote to depression. The community of people working towards climate mitigation and adaptation are so inspiring. They really make you think that change can happen and that you can—in fact, you must—be a part of it, in small ways and big. And the future of clean energy powered cities and sustainable agriculture and so on has so many other beneficial side effects that its crazy that we aren’t there already. A climate change resilient future is not one of deprivation and de-growth, at least not in the ways that matter.
So I knew I had to work on climate. But it’s odd, as someone 4 years out of a 6 year PhD, to try to work in a totally new field. I felt crazy knowing that there are people who are as expert in climate topics as I am in my niche neuro-modeling field, and yet I’m trying to contribute something at all to their work. And what about all my hard-earned neuroscience knowledge? Is it worth it—to me and to the field that trained me—to throw that away to become a novice in a new (though more important) area?
Then I learned about this position at NYU. I am currently a joint assistant professor of Psychology and Data Science. Granted, my computational work on the brain is the main reason for a Data Science title, I saw in that affiliation a chance to grow what had been a side hobby during my postdoc into a proper component of my research. So I am now advertising that, in addition to my work on neuroscience and psychology, my lab does computer vision for climate change. And while that is composed of just one project at the moment, I am excited to grow and work with more partners and students to help solve some of the ML problems people have while trying to save the world.
In some ideal setting, I could just keep working on the neuroscience and psychology and AI questions I find most interesting, without a care for the planet. But the world is far from ideal. There is a Good Place episode wherein it is revealed just how negatively impactful the simple act of buying a tomato can be on the world. I may want to just do interesting things everyday but my attempts to do that are contributing to the destruction of the planet and humanity. Knowing this makes every bit of time I spend not working on climate a pure indulgence.
Having this attitude makes the normal “stressors” of academic life feel less stressful. Applying to grants, writing papers…getting my grants and papers rejected… It’s all fine! I’m on borrowed time here. The fact that I get to spend any time speculating about the brain and mind is a gift. And I’m paying it forward by putting some effort into making a more sustainable planet, so that us humans can keep speculating on the brain and mind for years to come.
It also turns out that I find the climate work pretty academically stimulating. I just bought a textbook on remote sensing and I am itching to dive in. For whatever reason, I love thinking about vision, be it human or computer. Maybe in a different random seed of the universe I’d have been doing this work from the start.
To be clear, I don’t know if any of this will work out. I don’t know if academia is built for this kind of split interest. I don’t even really know how I’ll run my lab yet, logistically, with such different projects going on. But as climate futurist and writer Alex Steffen so beautifully informs us, discontinuity is the job. The way things were done in a pre-climate-change-aware era are no indication of how they will be done now. The change is coming, one way or another. And this is one small change I’m making.
I aimed to make my lab logo gently reflect these mixed priorities. I played around with the text-to-image generator Craiyon and ended up with a prompt along the lines of “brain with a sun in it logo”. One of the outputs was this pretty nice blue and yellow brain that I covered in purple to make it more NYU-y. The more I look at, the more I appreciate how much it represents: the sun and the blue indicate the climate, its placement near the occipital lobe highlights the visual system, and the sun’s reach across the brain captures the concept of attention—another favorite topic of mine. If a simple AI-generated lab logo can make it all work together, then hopefully I can too.


I wrote a book!
As some of you may know, in summer of 2018 I signed a contract with Bloomsbury Sigma to write a book about my area of research: computational neuroscience.
Though the term has many definitions, computational neuroscience is mainly about applying mathematics to the study of the brain. The brain—a jumble of all different kinds of neurons interconnected in countless ways that somehow produce consciousness—has been described as “the most complex object in the known universe”. Physicists for centuries have turned to mathematics to properly explain some of the most seemingly simple processes in the universe—how objects fall, how water flows, how the planets move. Equations have proved crucial in these endeavors because they capture relationships and make precise predictions possible. How could we expect to understand the most complex object in the universe without turning to mathematics?
The answer is we can’t, and that is why I wrote this book. While I’ve been studying and working in the field for over a decade, most people I encounter have no idea what “computational neuroscience” is or that it even exists. Yet a desire to understand how the brain works is a common and very human interest. I wrote this book to let people in on the ways in which the brain will ultimately be understood: through mathematical and computational theories.
At the same time, I know that both mathematics and brain science are on their own intimidating topics to the average reader and may seem downright prohibitory when put together. That is why I’ve avoided (many) equations in the book and focused instead on the driving reasons why scientists have turned to mathematical modeling, what these models have taught us about the brain, and how some surprising interactions between biologists, physicists, mathematicians, and engineers over centuries have laid the groundwork for the future of neuroscience.
Each chapter of Models of the Mind covers a separate topic in neuroscience, starting from individual neurons themselves and building up to the different populations of neurons and brain regions that support memory, vision, movement and more. These chapters document the history of how mathematics has woven its way into biology and the exciting advances this collaboration has in store.
Interested yet? Here is how you can get your hands on a copy:
UK & ebook publication date: March 4th, 2021. Bloomsbury | Hive | Waterstones | Amazon
India publication date: March 18th, 2021. Bloomsbury | Amazon
USA publication date: May 4th, 2021. Bloomsbury | Powell’s | Barnes & Noble | Amazon | Bookshop
AU/NZ publication date: May 4th, 2021. Bloomsbury | Boomerang | Amazon
Outside those countries? Bloomsbury UK ships globally so you can use that link, or Amazon, or just check with your normal bookseller. You can also get the e-book through Bloomsbury or however you normally get your e-books, and the audiobook is on Audible and elsewhere!
In addition to the standard websites, of course you can always check with your local independent book store or library. If it’s not there, ask if they’ll stock it!
The paperback (with a fresh blue cover) came out in Fall 2022. Remember, paperbacks are just like hardbacks except cheaper and with fewer errors, so get yours from any of the above sellers!
If you got the book, and read it, and want to tell the world your thoughts on it, head over to Goodreads or your local Amazon page to leave a review. Five stars particularly appreciated 🙂
There are also some translations (Chinese, Korean, Arabic, Turkish, and Japanese for now) in various stages of completion. Check language-specific book sellers for details!


EDIT: An updated and expanded form of this blogpost has been published as a review article in the Journal of Cognitive Neuroscience. If you would like to credit this post, please cite that article. The citation is:
Lindsay, Grace W. “Convolutional Neural Networks as a Model of the Visual System: Past, Present, and Future.” Journal of Cognitive Neuroscience (2020): 1-15.
And a pdf of the review can be found here: Convolutional Neural Networks as a Model of the Visual System: Past, Present, and Future
As with most of my recent blogging, I was moved to write this post due to a recent twitter discussion, specifically about how to relate components of a deep convolutional neural network (CNN) to the brain. However, most of the ideas here are things I’ve thought and talked about quite a bit. As someone who uses CNNs as a model of the visual system, I frequently (in research talks and other conversations) have to lay out the motivation and support for this choice. This is partly because they are (in some ways) a fairly new thing in neuroscience, but also because people are suspicious of them. Computational models generally can catch slack in neuroscience, largely (but not exclusively) from people who don’t use or build them; they’re frequently painted as too unrealistic or not useful. Throw into that atmosphere a general antipathy towards techbros and the over-hyping of deep learning/AI (and how much $$ it’s getting) and you get a model that some people just love to hate.
So what I’m trying to do here is use a simple (yet long…) Q&A format to paint a fairly reasonable and accurate picture of the use of CNNs for modeling biological vision. This sub-field is still very much in development so there aren’t a great many hard facts, but I cite things as I can. Furthermore, these are obviously my answers to these questions (and my questions for that matter), so take that for what it’s worth.
I’ve chosen to focus on CNNs as model of the visual system—rather than the larger question of “Will deep learning help us understand the brain?”—because I believe this is the area where the comparison is most reasonable, developed, and fruitful (and the area I work on). But there is no reason why this general procedure (specifying an architecture informed by biology and training on relevant data) can’t also be used to help understand and replicate other brain areas and functions. And of course it has been. A focus on this larger issue can be found here.
(I’m hoping this is readable for people coming either from machine learning or neuroscience, but I do throw around more neuroscience terms without definitions.)
1. What are CNNs?
Convolutional neural networks are a class of artificial neural networks. As such, they are comprised of units called neurons, which take in a weighted sum of inputs and output an activity level. The activity level is always a nonlinear function of the input, frequently just a rectified linear unit (“ReLu”) where the activity is equal to the input for all positive input and 0 for all non-positive input.
What’s special about CNNs is the way the connections between the neurons are structured. In a feedforward neural network, units are organized into layers and the units at a given layer only get input from units in the layer below (i.e. no inputs from other units at the same layer, later layers, or—in most cases—layers more than one before the current layer). CNNs are feedforward networks. However unlike standard vanilla feedforward networks, units in a CNN have a spatial arrangement. At each layer, units are organized into 2-D grids called feature maps. Each of these feature maps is the result of a convolution (hence the name) performed on the layer below. This means that the same convolutional filter (set of weights) is applied at each location in the layer below. Therefore a unit at a particular location on the 2-D grid can only receive input from units at a similar location at the layer below. Furthermore, the weights attached to the inputs are the same for each unit in a feature map (and different across feature maps).
After the convolution (and nonlinearity), a few other computations are usually done. One possible computation (though no longer popular in modern high-performing CNNs) is cross-feature normalization. Here the activity of a unit at a particular spatial location in a feature map is divided by the activity of units at the same location in other feature maps. A more common operation is pooling. Here, the maximum activity in a small spatial area of each each 2-D feature map grid is used to represent that area. This shrinks the size of the feature maps. This set of operations (convolution+nonlin[—->normalization]—> pooling) is collectively referred to as a “layer.” The architecture of a network is defined by the number of layers and choices about various parameters associated with them (e.g. the size of the convolutional filters, etc).

Most modern CNNs have several (at least 5) of these layers, the final of which feeds into a fully-connected layer. Fully-connected layers are like standard feedforward networks in that they do not have a spatial layout or restricted connectivity. Frequently 2-3 fully connected layers are used in a row and the final layer of the network performs a classification. If the network is performing a 10-way object classification, for example, the final layer will have 10 units and a softmax operation will be applied to their activity levels to produce a probability associated with each category.
These networks are largely trained with supervised learning and backpropagation. Here, pairs of images and their associated category label are given to the network. Image pixel values feed into the first layer of the network and the final layer of the network produces a predicted category. If this predicted label doesn’t match the provided one, gradients are calculated that determine how the weights (i.e. the values in the convolutional filters) should change in order to make the classification correct. Doing this many, many times (most of these networks are trained on the ImageNet database which contains over 1 million images from 1000 object categories) produces models that can have very high levels of accuracy on held-out test images. Variants of CNNs now reach 4.94% error rates (or lower), better than human-level performance. Many training “tricks” are usually needed to get this to work well such as smart learning rate choice and weight regularization (mostly via dropout, where a random half of the weights are turned off at each training stage).
Historically, unsupervised pre-training was used to initialize the weights, which were then refined with supervised learning. However, this no longer appears necessary for good performance.
For an in-depth neuroscientist-friendly introduction to CNNs, check out: Deep Neural Networks: A New Framework for Modeling Biological Vision and Brain Information Processing (2015)
2. Were CNNs inspired by the visual system?
Yes. First, artificial neural networks as whole were inspired—as their name suggests—by the emerging biology of neurons being developed in the mid-20th century. Artificial neurons were designed to mimic the basic characteristics of how neurons take in and transform information.
Second, the main features and computations done by convolutional networks were directly inspired by some of the early findings about the visual system. In 1962 Hubel and Wiesel discovered that neurons in primary visual cortex respond to specific, simple features in the visual environment (particularly, oriented edges). Furthermore, they noticed two different kinds of cells: simple cells—which responded most strongly to their preferred orientation only at a very particular spatial location—and complex cells—which had more spatial invariance in their response. They concluded that complex cells achieved this invariance by pooling over inputs from multiple simple cells, each with a different preferred location. These two features (selectivity to particular features and increasing spatial invariance through feedforward connections) formed the basis for artificial visual systems like CNNs.

Neocognitron
This discovery can be directly traced to the development of CNNs through a model known as the Neocognitron. This model, developed in 1980 by Kunihiko Fukushima, synthesized the current knowledge about biological visual in an attempt to build a functioning artificial visual system. The neocognitron is comprised of “S-cells” and “C-cells” and learns to recognize simple images via unsupervised learning. Yann LeCun, the AI researcher who initially developed CNNs, explicitly states that they have their roots in the neocognitron.
3. When did they become popular?
Throughout the history of computer vision, much work focused on hand-designing the features that were to be detected in an image, based on beliefs about what would be most informative. After filtering based on these handcrafted features, learning would only be done at the final stage, to map the features to the object class. CNNs trained end-to-end via supervised learning thus offered a way to auto-generate the features, in a way that was most suitable for the task.
The first major example of this came in 1989. When LeCun et al. trained a small CNN to do hand-written digit recognition using backprop. Further advances and proof of CNN abilities came in 1999 with the introduction of the MNIST dataset. Despite this success, these methods faded from the research community as the training was considered difficult and non-neural network approaches (such as support vector machines) became the rage.
The next major event came in 2012, when a deep CNN trained fully via supervised methods won the annual ImageNet competition. At this time a good error rate for 1000-way object classification was ~25%, but AlexNet achieved 16% error, a huge improvement. Previous winners of this challenge relied on older techniques such as shallow networks and SVMs. The advance with CNNs was aided by the use of some novel techniques such as the use of the ReLu (instead of sigmoid or hyperbolic tangent nonlinearities), splitting the network over 2 GPUs, and dropout regularization, This did not emerge out of nothing however, as a resurgence in neural networks can be seen as early as 2006. Most of these networks, however, used unsupervised pre-training. This 2012 advance was definitely a huge moment for the modern deep learning explosion.
Resources: Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review (2017)
4. When was the current connection between CNNs and the visual system made?
Much of the hullabaloo about CNNs in neuroscience today stems from a few studies published in ~2014. These studies explicitly compared neural activity recorded from humans and macaques to artificial activity in CNNs when the different systems were shown the same images.
The first is Yamins et al. (2014). This study explored many different CNN architectures to determine what leads to a good ability to predict responses of monkey IT cells. For a given network, a subset of the data was used to train linear regression models that mapped activity in the artificial network to individual IT cell activity. The predictive power on held-out data was used to assess the models. A second method, representational similarity analysis, was also used. This method does not involve direct prediction of neural activity, but rather asks if two systems are representing information the same way. This is done by building a matrix for each system, wherein the values represent how similar the response is for two different inputs. If these matrices look the same for different systems, then they are representing information similarly.

Representational Dissimilarity Matrices for different systems
By both measures, CNNs optimized for object recognition outperformed other models. Furthermore, the 3rd layer of the network better predicted V4 cell activity while the 4th (and final) layer better predicted IT. Indicating a correspondence between model layers and brain areas.
Another finding was that networks that performed better on object recognition also performed better on capturing IT activity, without a need to be directly optimized on IT data. This trend has largely held true for larger and better networks, up to some limits (see Q11).

Later layers of the CNN have a more similar representation to human IT
Another paper, Khaligh-Razavi and Kriegeskorte (2014), also uses representational similarity analysis to compare 37 different models to human and monkey IT. They too found that models better at object recognition better matched IT representations. Furthermore, the deep CNN trained via supervised learning (“AlexNet”) was the best performing and the best match, with later layers in the network performing better than earlier ones.
5. Did neuroscientists use anything like CNNs before?
Yes! The neocognitron model mentioned in Q2 was inspired by the findings of Hubel and Wiesel and went on to inspire modern CNNs, but it also spawned a branch of research in visual neuroscience recognized perhaps most visibly in the labs of Tomaso Poggio, Thomas Serre, Maximilian Riesenhuber, and Jim DiCarlo, among others. Models based on stacks of convolutions and max-pooling were used to explain various properties of the visual system. These models tended to use different nonlinearities than current CNNs and unsupervised training of features (as was popular in machine learning at the time as well), and they didn’t reach the scale of modern CNNs.
The path taken by visual neuroscientists and computer vision researchers has variously merged and diverged, as they pursued separate but related goals. But in total, CNNs can readily be viewed as a continuation of the modeling trajectory set upon by visual neuroscientists. The contributions from the field of deep learning relate to the computational power and training methods (and data) that allowed these models to finally become functional.
6. What evidence do we have that they “work like the brain”?
Convolutional neural networks have three main traits that support their use as models of biological vision: (1) they can perform visual tasks at near-human levels, (2) they do this with an architecture that replicates basic features known about the visual system, and (3) they produce activity that is directly relatable to the activity of different areas in the visual system.

To start, by their very nature and architecture, they have two important components of the visual hierarchy. First, receptive field sizes of individual units grow as we progress through the layers of the network just as they do as we progress from V1 to IT. Second, neurons respond to increasingly complex image features as we progress through the layers just as tuning goes from simple lines in V1 to object parts in IT. This increase in feature complexity can be seen directly through visualization techniques available in CNNs.

Visualizations of what features the network learns at different layers
Looking more deeply into (3), many studies subsequent to the original 2014 work (Q4) have further established the relationship between activity in CNNs and the visual systems. These all show the same general finding: the activity of artificial networks can be related to the activity of the visual system when both are shown the same images. Furthermore, later layers in the network correspond to later areas in the ventral visual stream (or later time points in the response when using methods such as MEG).
Many different methods and datasets have been used to make these points, as can be seen in the following studies (amongst others): Seibert et al. (2016) Cadena et al. (2017), Cichy et al. (2016), Wen et al. (2018), Eickenberg et al. (2017), and van Gerven (2015), and Seeliger et al. (2017).

Correlation between the representations at different CNN layers and brain areas (from Cichy et al.)
The focus of these studies is generally on the initial neural response to briefly-presented natural images of various object categories. Thus, these CNNs are capturing what’s been referred to as “core object recognition,” or “the ability to rapidly discriminate a given visual object from all other objects even in the face of identity-preserving transformations (position, size, viewpoint, and visual context).” In general, standard feedforward CNNs best capture the early components of the visual response, suggesting they are replicating the initial feedforward sweep of information from retina to higher cortical areas.
The fact that the succession of neural representations created by the visual system can be replicated by CNNs suggests that they are doing the same “untangling” process. That is, both systems take representations of different object categories that are inseparable at the image/retinal level and create representations that allow for linear separability.
In addition to comparing activities, we can also delve deeper into (1), i.e., the performance of the network. Detailed comparisons of the behavior of these networks to humans and animals can further serve to verify their use as a model and identify areas where progress is still needed. The findings from this kind of work have shown that these networks can capture patterns of human classification behavior better than previous models in multiple domains (and even predict/manipulate it), but fall short in certain specifics such as how performance falls off with noise, or when variations in images are small.
Such behavioral effects have been studied in: Rajalingham et al. (2018), Kheradpishesh et al. (2015), Elsayed et al. (2018), Jozwik et al. (2017), Kubilius et al. (2016), Dodge and Karam (2017), Berardino et al. (2017), and Geirhos et al. (2017).
Whether all this meets the specification of a good model of the brain is probably best addressed by looking at what people in vision have said they wanted out of a model of the visual system:
“Progress in understanding the brain’s solution to object recognition requires the construction of artificial recognition systems that ultimately aim to emulate our own visual abilities, often with biological inspiration (e.g., [2–6]). Such computational approaches are critically important because they can provide experimentally testable hypotheses, and because instantiation of a working recognition system represents a particularly effective measure of success in understanding object recognition.” – Pinto et al., 2007
From this perspective it’s clear that CNNs do not represent a moving of the target in vision science, but more a reaching of it.
7. Can any other models better predict the activity of visual areas?
Generally, no. Several studies have directly compared the ability of CNNs and previous models of the visual system (such as HMAX) to capture neural activity. CNNs come out on top. Such studies include: Yamins et al. (2014), Cichy et al. (2017), and Cadieu et al. (2014).
8. Are CNNs mechanistic or descriptive models of the visual system?
A reasonable definition of a mechanistic model is one in which internal parts of the model can be mapped to internal parts of the system of interest. Descriptive models, on the other hand, are only matched in their overall input-output relationship. So a descriptive model of the visual system may be one that takes in an image and outputs an object label that aligns with human labels, but does so in a way that has no obvious relation to the brain. As described above, however, layers of a CNN can be mapped to areas of the brain. Therefore, CNNs are mechanistic models of the representational transformation carried out by the ventral system as it does object recognition.
For a CNN to, as a whole, be a mechanistic model does not require that we accept that all sub-components are mechanistic. Take as an analogy, the use of rate-based neurons in traditional circuit models of the brain. Rate-based neural models are simply a function that maps input strength to output firing rate. As such, these are descriptive models of neurons: there are no internal components of the model that relate to the neural processes that lead to firing rate (detailed bio-physical models such as Hodgkin-Huxley neurons would be mechanistic). Yet we can still use rate-based neurons to build mechanistic models of circuits (an example I’m fond of). All mechanistic models rely on descriptive models as their base units (otherwise we’d all need to get down to quantum mechanics to build a model).
So are the components of a CNN (i.e. the layers—comprised of convolutions, nonlinearities, possibly normalization, and pooling) mechanistic or descriptive models of brain areas? This question is harder to answer. While these layers are comprised of artificial neurons which could plausibly be mapped to (groups of) real neurons, the implementations of many of the computations are not biological. For example, normalization (in the networks that use it) is implemented with a highly-parameterized divisive equation. We believe that these computations can be implemented with realistic neural mechanisms (see the above-cited example network), but those are not what are at present used in these models (though I, and others, are working on it… see Q12).
9. How should we interpret the different parts of a CNN in relationship to the brain?
For neuroscientists used to dealing with things on the cellular level, models like CNNs may feel abstracted beyond the point of usefulness (cognitive scientists who have worked with abstract multi-area modeling for some time though may find them more familiar).

But even without exact biological details, we can still map components of the CNN to components of the visual system. First, inputs to a CNN are usually 3-D (RGB) pixel values that have been normalized or whitened in some way, roughly corresponding to computations performed by the retina and lateral geniculate nucleus. The convolutions create feature maps that have a spatial layout, like the retinotopy found in visual areas, which means that each artificial neuron has a spatially-restricted receptive field. The convolutional filter associated with each feature map determines the feature tuning of the neurons in that feature map. Individual artificial neurons are not meant to be mapped directly to individual real neurons; it may be more reasonable to think of individual units as cortical columns.
Which layers of the CNN correspond to which brain areas? The early work using models that only contained a small number of layers provided support for a one layer to one brain area mapping. For example, in Yamins et al. (2014), the final convolutional layer best predicts IT activity and the second to last best predicts V4. The exact relationship, however, will depend on the model used (with deeper models allowing for more layers per brain area).
The fully connected layers at the end of a convolutional network have a more complicated interpretation. Their close relationship to the final decision made by the classifier and the fact that they no longer have a retinotopy makes them prefrontal cortex-like. But they also may perform well when predicting IT activity.
10. What does the visual system have that CNNs don’t have?
Lots of things. Spikes, saccades, separate excitatory and inhibitory cells, dynamics, feedback connections, feedforward connections that skip layers, oscillations, dendrites, [***inhale****] cortical layers, neuromodulators, fovea, lateral connections, different cell types, binocularity, adaptation, noise, and probably whatever your favorite detail of the brain is.
Of course these are features that the most standard CNNs used as models today don’t have by default. But many of them have already been worked into newer CNN models, such as: skip connections, feedback connections, saccades, spikes, lateral connections, and a fovea.
So clearly CNNs are not direct replicas of primate vision. It should also be clear that this fact is not disqualifying. No model will be (or should be) a complete replica of the system of interest. The goal is to capture the features necessary to explain what we want to know about vision. Different researchers will want to know different things about the visual system, and so the absence of a particular feature will matter more or less to one person than to someone else. Which features are required in order to, say, predict the response of IT neurons averaged over the first ~100ms of image presentation? This is an empirical question. We cannot say a priori that any biological feature is necessary or that the model is a bad one for not having it.
We can say that a model without details such as spiking, E-I types, and other implementation specifics is more abstract than one that has those. But there’s nothing wrong with abstraction. It just means we’re willing to separate problems out into a hierarchy and work on them independently. One day we should be able to piece together the different levels of explanation and have a model that replicates the brain on the large and fine scale. But we must remember not to make the perfect the enemy of the good on that quest.
11. What do CNNs do that the visual system doesn’t do?
This, to me, is the more relevant question. Models that use some kind of non-biological magic to get around hard problems are more problematic than those that lack certain biological features.
First issue: convolutional weights are positive and negative. This means that feedforward connections are excitatory and inhibitory (whereas in the brain connections between brain areas are largely excitatory) and that individual artificial neurons can have excitatory and inhibitory influences. This is not terribly problematic if we simply consider that the weights indicate net effects, which may in reality be executed via feedforward excitatory connections to inhibitory cells.
Next: weights are shared. This means that a neuron at one location in a feature map uses the exact same weights on its inputs as a different neuron in the same feature map. While it is the case that something like orientation tuning is represented across the retinotopic map in V1, we don’t believe that a neuron that prefers vertical lines in the one area of visual space has the *exact same* input weights as a vertical-preferring neuron at another location. There is no “spooky action at a distance” that ensures all weights are coordinated and shared. Thus, the current use of weight sharing to help train these networks should be able to be replaced by a more biologically plausible way of creating spatially-invariant tuning.
Third: what’s up with max-pooling? The max-pooling operation is, in neuroscience terms, akin to a neuron’s firing rate being equal to the firing rate of its highest firing input. Because neurons pool from many neurons, it’s hard to devise a neuron that could straightforwardly do this. But the pooling operation was inspired by the discovery of complex cells and originally started as an averaging operation, something trivially achievable by neurons. Max-pooling, however, has been found to be more successful in terms of object recognition performance and fitting biological data and is now widely used.
The further development of CNNs by machine learning researchers have taken them even farther away from the visual system (as the goal for ML people is performance alone). Some of the best performing CNNs now have many features that would seem strange from a biological perspective. Furthermore, the extreme depths of these newer models (~50 layers) has made their activity less relatable to the visual system.
There is also of course the issue of how these networks are trained (via backpropagation). That will be addressed in Q13.
12. Can they be made to be more like the brain?
One of the main reasons I’m a computational neuroscientist is because (without the constraints of experimental setups) we can do whatever we want. So, yes! We can make standard CNNs have more biology-inspired features. Let’s see what’s been done so far:
As mentioned above in Q10, many architectural elements have been added to different variants of CNNs, which make them more similar to the ventral stream. Furthermore, work has been done to increase the plausibility of the learning procedure (see Q13).
In addition to these efforts, some more specific work to replicate biological details includes:
Spoerer et al. (2017) which, inspired by biology, shows how adding lateral and feedback connections can make models better at recognizing occluded and noisy objects.

Adding biologically-inspired connections, in Spoerer et al.
Some of my own work (presented at Cosyne 2017 and in preparation for journal submission) involves putting the stabilized supralinear network (a biologically-realistic circuit model that implements normalization) into a CNN architecture. This introduces E and I cell types, dynamics, and recurrence to CNNs.
Costa et al. (2017) implemented long-short-term-memory networks using biologically-inspired components. LSTMs are frequently used when adding recurrence to artificial neural networks, so determining how their functions could be implemented biologically is very useful.
13. Does it matter that CNNs use backpropagation to learn their weights?
Backpropagation involves calculating how a weight anywhere in the network should change in order to decrease the error that the classifier made. It means that a synapse at layer one would have some information about what went wrong all the way at the top layer. Real neurons, however, tend to rely on local learning rules (such as Hebbian plasticity), where the change in weight is determined mainly by the activity of the pre- and post-synaptic neuron, not any far away influences. Therefore, backprop does not seem biologically realistic.
This doesn’t need to impact our interpretation of the fully-trained CNN as a model of the visual system. Parameters in computational models are frequently fit using techniques that aren’t intended to bear any resemblance to how the brain learns (for example Bayesian inference to get functional connectivity). Yet that doesn’t render the resulting circuit model uninterpretable. In an extreme view, then, we can consider backpropagation as merely a parameter-fitting tool like any other. And indeed, Yamins et al. (2014) did use a different parameter fitting technique (not backprop).
However taking this view does mean that certain aspects of the model are not up for interpretation. For example, we wouldn’t expect the learning curve (that is, how the error changes as the model learns) to relate to the errors that humans or animals make when learning.

Local error calculations with segregated dendrite in Guerguiev et al.
While the current implementation of backprop is not biologically-plausible, it could be interpreted as an abstract version of something the brain is actually doing. Various efforts to make backprop biologically plausible by implementing it with local computations and realistic cells types are underway (for example, this and this). This would open up the learning process to better biological interpretation. Whether the use of more biologically plausible learning procedures leads to neural activity that better matches the data is an as-yet-unanswered empirical question.
On the other hand, unsupervised learning seems a likely mechanism for the brain as it doesn’t require explicit feedback about labels, but rather uses the natural statistics of the environment to develop representations. Thus far, unsupervised learning has not been able to achieve the high object categorization performance reached by supervised learning. But advances in unsupervised learning and methods to make it biologically plausible may ultimately lead to better models of the visual system.
14. How can we learn about the visual system using CNNs?
Nothing can be learned from CNNs in isolation. All insights and developments will need to be verified and furthered through an interaction with experimental data. That said, there are three ways in which CNNs can contribute to our understanding of the visual system.
The first is to verify our intuitions. To paraphrase Feynman “we don’t understand what we can’t build.” For all the data collected and theories developed about the visual system, why couldn’t neuroscientists make a functioning visual system? That should be alarming in that it signifies we were missing something crucial. Now we can say our intuitions about the visual system were largely right, we were just missing the computing power and training data.
The second is to allow for an idealized experimental testing ground. This is a common use of mechanistic models in science. We use existing data to establish a model as a reasonable facsimile of what we’re interested in. Then we poke, prod, lesion, and lob off parts of it to see what really matters to the functioning. This serves as hypothesis generation for future experiments and/or a way to explain previous data that wasn’t used to build the model.
The third way is through mathematical analysis. As is always the case with computational modeling, putting our beliefs about how the visual system works into concrete mathematical terms opens them up to new types of investigation. While doing analysis on a model usually requires simplifying it even further, it can still offer helpful insights about the general trends and limits of a model’s behavior. In this particular case, there is extra fire power here because some ML researchers are also interested in mathematically dissecting these models. So their insights can become ours in the right circumstance (for example).
15. What have we learned from using CNNs as a model of the visual system?
First, we verified our intuitions by showing they can actually build a functioning visual system. Furthermore, this approach has helped us to define the (in Marr’s terms) computational and algorithmic levels of the visual system. The ability to capture so much neural and behavioral data by training on object recognition suggests that is a core computational role of the ventral stream. And a series of convolutions and pooling is part of the algorithm needed to do it.
The success of these networks has also, I believe, helped allow for a shift in what we consider the units of study in visual neuroscience. Much of visual neuroscience (and all neuroscience…) has been dominated by an approach that centers individual cells and their tuning preferences. Abstract models that capture neural data without a strict one neuron-to-one neuron correspondence put the focus on population coding. It’s possible that trying to make sense of individual tuning functions would someday yield the same results, but the population-level approach seems more efficient.
Furthermore, viewing the visual system as just that—an entire system—rather than isolated areas, reframes how we should expect to understand those areas. Much work has gone into studying V4, e.g., by trying to describe in words or simple math what causes cells in that area to respond. When V4 is viewed as a middle ground on a path to object recognition, it seems less likely that it should be neatly describable on its own. From this review: “A verbal functional interpretation of a unit, e.g., as an eye or a face detector, may help our intuitive understanding and capture something important. However, such verbal interpretations may overstate the degree of categoricality and localization, and understate the statistical and distributed nature of these representations.” Indeed, analysis of trained networks has indicated that strong, interpretable tuning of individual units is not correlated with good performance, suggesting the historic focus on that has been misguided.
Some more concrete progress is coming from exploring different architectures. By seeing which details are required for capturing which elements of the neural and behavioral response, we can make a direct connection between structure and function. In this study, lateral connections added to the network did more to help explain the time course of the dorsal stream’s response than the ventral stream’s. Other studies have suggested that feedback connections will be important for capturing ventral stream dynamics. It’s also been shown that certain components of the neural response can be captured in a model with random weights, suggesting the hierarchical architecture alone can explain them. While other components requiring training on natural and valid image categories.
Furthermore, observing that certain well-performing CNNs (see Q11) are not capable of accurately predicting neural activity is important because it indicates that not all models that do vision will be good models of the brain. This lends credence to the idea that the architectures that we have seen predict neural activity well (with a correspondence between brain areas and layers) do so because they are indeed capturing something about the transformations the brain does.
Because CNNs offer an “image computable” way of generating realistic neural responses, they are also useful for relating lesser understood signals to visual processing, as has been done here and here for contextualizing oscillations.
Using CNNs as a model of the visual system, my own work has focused on demonstrating that the feature similarity gain model (which describes the neural impacts of attention) can explain attention’s beneficial performance effects.
Finally, some studies have documented neural or behavioral elements (see Q6) not captured by CNNs. These help identify areas that need further experimental and computational exploration.
And there are more examples (for a complete collection of papers that compare CNNs to the brain see this list from Martin Hebart). All in all I would say not a bad amount, given that much of this has really only been going on in earnest since around 2014.
A piece I wrote has just been published in the online magazine Aeon. It tries to tackle the question of whether AI—currently powered by artificial neural networks—actually works like the brain. And perhaps more importantly (because no one article could definitively answer such a big question), it lays out some ideas on how we could even approach the topic.
As a computational neuroscientist, this topic (including the more philosophical question of what counts as “works like,” which is always implicit in computational modeling) is deeply interesting to me and I’d love to write a lot more about it.
But for now, I hope you enjoy reading (or listening to) this piece!
Planes don’t flap their wings; does AI work like the brain?
(also, unexpected content warning: multiple references to faeces and digestion…)
A recent twitterstorm involving claims about the ascendance of theories of “panpsychism” and the damage that poor philosophizing can do to the study of consciousness has gotten me thinking about consciousness as a scientific study again. I (some 5 and a half years ago) wrote about the sorry treatment consciousness gets from mainstream neuroscientists. At the risk of becoming the old curmudgeon I rallied against then, I’d like to revisit the topic and (hopefully) add some clarity to the critiques.
I don’t know enough about the state of academic philosophy of mind to weigh in on the panpsychism debate, which seemed to set this all off (though of course I do intuitively believe panpsychism to be nonsense…). But the territorial arguments over who gets to talk about consciousness (philosophers v scientists essentially) is relevant to the sub-debate I care about. Essentially, why do neuroscientists choose to use the C-word? What kind of work counts as “consciousness” work that couldn’t just as well be called attention, perception, memory etc work? As someone who does attention research, I’ve butted up against these boundaries before and always chosen to stay clearly on my side of things. But I’ve definitely used the results of quote-unquote consciousness studies to inform my attention work, without seeing much of a clear difference between the two. (In fact, in the Unsupervised Thinking episode, What Can Neuroscience Say About Consciousness?, we cover an example of this imperceptible boundary, and a lot of the other issues I’ll touch on here).
Luckily Twitter allows me to voice such questions and have them answered by prominent consciousness researchers. Here’s some of the back and forth:
I think consciousness is the subject of more worry & scrutiny because it claims to be something more. If it’s really frameable as attention or memory, why claim to study consciousness? Buzz words bring backlash
— Grace Lindsay (@neurograce) February 1, 2018
hi @neurograce, but i don’t think @trikbek means consciousness is framed / frameable as attention or memory. he meant it is frameable in the same ways, i.e. as cognitive mechanisms. the mechanisms are different, so we need to work on it too. when done right it isn’t just buzz
— hakwan lau (@hakwanlau) February 1, 2018
Sure, I understand that meaning. But many times I see consciousness work that really is indistinguishable from e.g. attention or psychophysics. Seems like word choice & journal is what makes it consciousness (& perhaps motivation for that comes from its buzziness)
— Grace Lindsay (@neurograce) February 1, 2018
that’s right. since the field is still at its infancy, a lot of work that isn’t strictly about the phenomenon tags along. but i think at this point we do have enough work directly about the difference between conscious vs unconscious processing, rather than attention / perception
— hakwan lau (@hakwanlau) February 1, 2018
I took @neurograce‘s critique to mean that there seem to be conceptual gaps in making the distinction between conscious processing vs. vanilla attention/perception. Is the distinction crystal clear, @hakwanlau?
— Venkat Ramaswamy (@VenkRamaswamy) February 3, 2018
@VenkRamaswamy . yes, to my mind it is clear. 🙂 https://t.co/YLq5pNurng
— hakwan lau (@hakwanlau) February 3, 2018
And with that final tweet, Hakwan links to this paper: What Type of Awareness Does Binocular Rivalry Assess?. I am thankful for Hakwan’s notable willingness to engage with these topics (and do so politely! on Twitter!). Nevertheless I am now going to lay out my objections to his viewpoint…
Particularly, I’d like to focus on a distinction made in that paper that seems to be at the heart of what makes something consciousness research, rather than merely perception research, and that is the claimed difference between “perceptual awareness” and “subjective awareness”. Quoting from the paper:
Perceptual awareness constitutes the visual system’s ability to process, detect, or distinguish among stimuli, in order to perform (i.e., give responses to) a visual task. On the other hand, subjective awareness constitutes the visual system’s ability to generate a subjective conscious experience. While the two may seem conceptually highly related, operationally they are assessed by comparing different task conditions (see Fig. 1): to specifically assess subjective awareness but not perceptual awareness, one needs to make sure that perceptual performance is matched across conditions.
And here is that Figure 1:

The contents of the thought bubble I assume (crucially) are given to the experimenter via verbal report, and that is how one can distinguish between (a) and (c).
To study consciousness then, experimental setups must be designed where the perceptual awareness and task performance remains constant across conditions, while subjective awareness differs. That way, the neural differences observed across conditions can be said to underly conscious experience.
My issue with this distinction is that I believe it implicitly places verbal self-report on a pedestal, as the one true readout of subjective experience. In my opinion, the verbal self-report by which one is supposed to gain access to subjective experience is merely a subset of the ways in which one would measure perceptual awareness. Again, the definition of perceptual awareness is: the visual system’s ability to process, detect, or distinguish among stimuli, in order to perform (i.e., give responses to) a visual task. In many perception/psychophysics experiments responses are given via button presses or eye movements. But verbal report could just as well be used. I understand that under certain circumstances (blindsight being a dramatic example), performance via verbal report will differ from performance via ,e.g., arm movement. But scientifically, I don’t think the leap can be made to say that verbal report is anyway different than any other behavioral readout. Or at least, it’s not in anyway more privileged at assessing actual subjective conscious experience in any philosophically interesting way. One way to highlight this issue: How could subjective awareness be studied in non-verbal animals? And if it can’t be, what would that imply about the conscious experience of those animals? Or what if I trained an artificial neural network to both produce speech and move a robotic arm. Would a discrepancy between those readouts allow for the study of its subjective experience?
Another way to put this–which blurs the distinction between this work and vanilla perceptual science–is that there are many ways to design an experiment in perception studies. And the choices made (duration of the stimulus, contextual clues, choice of behavioral readout mechanism) will definitely impact the results. So by all means people should document the circumstances under which verbal report differs from others, and look at the neural correlates of that. But why do we choose to call this subset of perceptual work consciousness studies, knowing all the philosophical and cultural baggage that word comes with?
I think it has to do with our (and I mean our, because I share them) intuitions. When I first heard about blindsight and split brain studies I had the same immediate fascination with them as most scientists, because of the information I believed they conveyed about consciousness. I even chose a PhD thesis that let me be close to this kind of stuff. And I still do intuitively believe that these kinds of studies can provide interesting context for my own conscious experience. I know that if I verbally self-reported not seeing an apple that I would mean that as an indication of my subjective visual experience, and so I of course see why we immediately assume that it could be used as a readout of that. I just think that technically speaking there is no actual way to truly measure subjective experience; we only have behavioral readouts. And of course we can imagine situations where, for whatever reason, a person’s verbal self-report isn’t a reflection of their subjective experience. And basing a measure solely on our own intuitions and calling it a measure of consciousness isn’t very good science.
It’s possible that this just seems like nitpicking. But Hawkan himself has raised concerns about the reputation of consciousness science as being non-rigorous. To do rigorous science, sometimes you have to pick a few nits.
====================================================
Addendum! A useful followup via Twitter that helps clarify my position
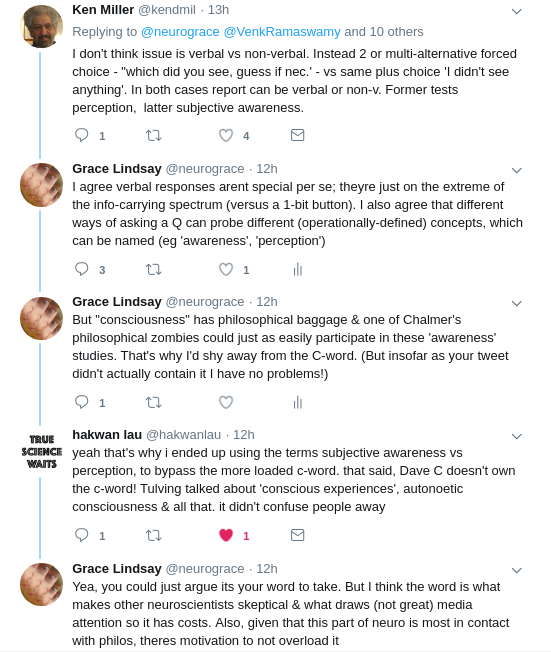
Current wisdom says that–with the exception of those that go on to great scientific fame–a PhD student’s thesis will be read by at most the 5 or so professors on their dissertation committee. Because most of the content in a thesis is already or soon-to-be published as separate papers this is not much of a loss. However, the introduction to a thesis is something that is usually written special-purpose for that document and rarely has another outlet for publication. These introductions, however, offer a space for young researchers to catalogue their journey through the scientific literature and share some accumulated wisdom from years of learning to do science. So to get a little more mileage out of my own thesis introduction and encourage others to do the same, I’ve published it here, along with links to where elements of each chapter of the thesis work are available online.
Thesis Abstract: Perception is the result of more than just the unbiased processing of sensory stimuli. At each moment in time, sensory inputs enter a circuit already impacted by signals of arousal, attention, and memory. This thesis aims to understand the impact of such internal states on the processing of sensory stimuli. To do so, computational models meant to replicate known biological circuitry and activity were built and analyzed. Part one aims to replicate the neural activity changes observed in auditory cortex when an animal is passively versus actively listening. In part two, the impact of selective visual attention on performance is probed in two models: a large-scale abstract model of the visual system and a smaller, more biologically-realistic one. Finally in part three, a simplified model of Hebbian learning is used to explore how task context comes to impact prefrontal cortical activity. While the models used in this thesis range in scale and represent diverse brain areas, they are all designed to capture the physical processes by which internal brain states come to impact sensory processing.
Thesis Introduction
This thesis takes a computational approach to the task of understanding how internal brain states and representations of sensory inputs combine. In particular, mathematical models of neural circuits are built to replicate and elucidate the physical processes by which internal state modulates sensory processing. Ultimately, this work should contribute to an understanding of how complex behavior arises from neural circuits.
Cognition is the result of internal state and external influences
While the neural mechanisms that underly it remain an open question to this day, the observation that internal mental state causes changes in sensory perception dates back millennia [Hatfield, 1998]. One of the earliest such observations comes from Aristotle in 350 B.C.E. in his treatise On Sense and the Sensible, wherein he remarks that “…persons do not perceive what is brought before their eyes, if they are at the time deep in thought, or in a fright, or listening to some loud noise.” The notion that internal state can be purposefully controlled in order to enhance processing was also noted by Lucretius in the first century B.C.E: “Even in things that are plainly visible, you can note that if you do not direct the mind, the things are, so to speak, far removed and remote for the whole time.” Philosophers continued to make these observations for centuries, with Descartes, for example, writing in 1649 that, “The soul can prevent itself from hearing a slight noise or feeling a slight pain by attending very closely to some other thing…” While these early documentations provide evidence that this phenomenon is universal and perceptually relevant, a more direct link to the field of experimental psychology comes in the early 18th century through the work of Gottfried Leibniz. While Leibniz’s work posits many elements considered outside the realm of today’s science, he does provide insights on the role of memory (plausibly a form of internal state) on sensory processing: “It is what we see in an animal that has a perception of something striking of which it has previously had a similar perception; the representations in its memory lead it to expect this time the same thing that happened on the previous occasion, and to have the same feelings now as it had then” [Leibniz, 2004]. He also, through the notion of “apperception,” expounded on the ways in which motivation and will influence perception. But the particular significance of Leibniz’s work for modern psychology comes through his influence on Wilhelm Wundt. Wundt, who founded what is considered the first experimental psychology lab in 1879, is explicit about the role of Leibniz’s work in his own thought. With a particular focus on the notion of “apperception,” Wundt took up the task of scientifically measuring and studying central mental control processes [Rieber and Salzinger, 2013]. Modern studies of internal state and sensory processing are direct descendants of his initial work on developing the field of experimental psychology.
Through centuries of experimental research, a myriad of ways in which internal state can impact processing have been documented. Arousal levels, for example, have been shown to impact perceptual thresholds and reaction times in an inverted-U manner [Tomporowski and Ellis, 1986]; that is, beneficial effects on perception come from moderate levels of arousal, while too low or too high arousal can impair performance. When awakened from sleep (and presumably in a state of low arousal), people are slower to respond to auditory stimuli [Wilkinson and Stretton, 1971]. Under conditions of sleep deprivation, responses to visual stimuli are slower and misses are more common [Belenky et al., 2003]. In the study of human psychology, mood and emotional state have also been related to changes in sensory processing. For example, patients with major depressive disorder showed higher thresholds for odor detection than healthy controls, but this difference went away after successful treatment [Pause et al., 2001].
Selective attention differs from arousal and mood in that it is controllable and directed to a subset of the perceptual experience. When participants expect a stimulus in a given sensory modality (e.g. a visual input), they are slower to respond to a relevant stimulus in a different modality (e.g. a tactile one) [Spence et al., 2001]. When cued to attend to a subset of the input within a sensory modality, similar benefits and costs are found for the attended and unattended stimuli, respectively [Carrasco, 2011]. In a particularly well-known example of “inattentional blindness,” subjects asked to count the number of basketball passes in a video did not report awareness of a person in a gorilla suit walking across the frame [Simons and Chabris, 1999].
Interestingly, the internal state generated by a stimulus in one sensory modality may also alter the perception from another. For example, hearing animal noises prior to image presentation increases detection of animal images and lowers reaction time [Schneider et al., 2008]. In addition, certain forms of memory and stimulus history within a modality can impact sensory processing. For example, trial history has complex effects on future behavior that are at least in part due to changes in stimulus expectation as well as low-level sensory facilitation [Cho et al., 2002].
While this ability of internal state to alter perception and decision-making seems perhaps a hallmark of mammalian, or even primate, neurophysiology, it has been observed across the evolutionary tree [Lovett-Barron et al., 2017]. For example, being in a food-deprived state alters the response of C. elegans to chemical gradients [Ghosh et al., 2016].
Different types of internal state modulation are believed to have different neural underpinnings. Overall arousal levels, for example, have broad impacts on various sensory and cognitive functions. A likely candidate for such modulation is thus the brainstem, as it contains nuclei that send diffuse connections across the brain [Sara and Bouret, 2012]. The axons from these areas release a cocktail of neuromodulators that can have diverse impacts. For example, noradrenaline released from the locus coeruleus is believed to play a role in neural synchronization [Sara and Bouret, 2012]. Switching between tasks that have different goals or require information from different sensory modalities, however, requires more targeted manipulations that can impact different brains areas separably. In a study that monitored fMRI activity during switches between auditory and visual attention, activity in frontal and parietal cortices were correlated with the switch [Shomstein and Yantis, 2004]. Further along this spectrum, selective attention within a sensory modality implies a targeting of individual cell populations that represent the attended stimulus. Such fine-grained modulation by attention has been observed [Martinez-Trujillo and Treue, 2004], and is assumed to be controlled by top-down connections originating in the frontal cortex [Bichot et al., 2015].
The alteration of sensory processing by internal state is an important component of the cognitive processes that lead to adaptive behavior. Allowing perception to be influenced by context, goals, and history creates a more flexible mapping between sensory input and behavioral output. This can be viewed as a useful integration of many different information sources for the purposes of decision-making. The importance of this is made clear by the cases in which it goes wrong. An underlying cognitive deficit in schizophrenia, for example, is the inability to incorporate context into perceptual processing [Bazin et al., 2000].
Circuit modeling as an approach for connecting structure and function
The notion that structure begets function in the brain has appeared throughout the history of neuroscience. Even without any significant evidence, phrenologists proposed different anatomical foci for different cognitive functions [Parssinen, 1974], so natural is the structure-function relationship. Some of the earliest examples of observed structure being related to function came in the late 19th century from Santiago Ramón y Cajal. Through careful anatomical investigation of a variety of neural circuits, Cajal came to hypothesize—correctly—that a “nervous current” travels from the dendritic tree through the soma and out through the axon [Llinás, 2003]. This relationship between structure and function extends beyond individual neuron morphology to the structure of entire circuits. The presence of a repeating laminar circuit motif—with, for example, inputs from lower areas targeting cells in layer 4, which project to cells in layers 2/3, which send outputs to layer 5—is frequently cited as evidence that such structure is a functional unit of the brain [Douglas and Martin, 2004]. A more direct investigation of how the structure of neural connections leads to functionally-interpretable activity came from Hubel and Weisel. Particularly, they documented two different types of neurons in primary visual cortex—simple cells (which respond to on- and off-patterns of light with spatial specificity) and complex cells (which have more spatial invariance in their responses to light patterns)—and came to the conclusion that the responses of the complex cells could be understood if it is assumed that they receive input from multiple simple cells, each representing a slightly different spatial location [Hubel and Wiesel, 1962]. Thus, the connections of the neural circuit were mapped to functional properties of the neural responses. This level of understanding should ultimately be possible for all neural responses, insofar as all are the result of the neuron’s place in a circuit.
While experimental results have facilitated an understanding of the importance of structure in neural circuits, such descriptive approaches have limitations. To truly understand a neural circuit, as Richard Feynman would say, we must be able to build it. Mathematical models allow for the precise formulation and testing of a hypothesis. In neural circuit modeling, neurons are represented by an equation or set of equations that represent how the neuron’s inputs are combined and transformed into an output measure, such as firing rate. A weight matrix dictates the impact any given neuron’s activity has on other neurons in the network. When designed to incorporate facts about the connectivity and neural response properties of a particular brain area, circuit models can serve as powerful mechanistic explanation of neural activity. As such, they can be used to test and generate hypotheses about the relationship between structure and activity. In neuroscience, where tools for observation and manipulation are limited and/or expensive, being apply to perform experiments in silico can be of immense value. Furthermore, mathematical analysis and simulation is of particular use when working with large and complex systems, which can display counterintuitive and difficult-to-predict behavior.
Circuit modeling exists within a larger set of quantitative approaches that comprise computational/theoretical neuroscience. Other approaches in this category focus on devising advanced tools for data analysis tailored to the problems of neuroscience. Another subset of methods involves more abstract mathematical analysis for the purpose of deriving statements about qualities such as optimality, stability, or memory capacity. While these other quantitative approaches have much to offer the field, circuit modeling is particularly well-suited for incorporating and explaining data. Theoretical constructs are only useful insofar as they can be related to biologically observable values, and circuit models are built to be directly comparable to existing biological structures. Therefore, predications from a circuit model are straightforward to interpret, and lead to predictions for the data. Practically, certain predictions from circuit models may be difficult to explore experimentally due to technical limitations. However, this creates a role for theory in driving the development of tools, as circuit models make clear which components of the biology are most worth measuring.
To encourage an integration of experimental and computational work, it is important for there to be a common language and set of ideas. Practically speaking, this can be achieved by building models that have explicit one-to-one correspondence with biological entities. It is also helpful to design models in a way that allows for the same set of analyses to be performed on the data as well as the model. In this case then, even if a one-to-one correspondence isn’t possible, derivative measurements can still be compared directly. This thesis contains examples from along this spectrum. A tension that always comes with model building, however, is the desire to make a model that is both detailed and accurate while also conceptually useful. Highly detailed, complex models may be good at capturing the data but can be unwieldy and do not open themselves up for easy mathematical, or even informal conceptual, inspection. While simpler models can be worked with and interrogated more easily, the rich dynamics of the brain is unlikely to be captured by a simple model. Again, this thesis includes models from across this spectrum.
Thesis overview
The parts of this thesis are arranged according to the brain area studied as well as the type of internal state being explored.
In the first, the impact of task engagement on responses in mouse auditory cortex is explored. The modeling approach used in this chapter allows for a direct comparison of the firing rates of different neuronal subtypes in the model with those found experimentally under two circumstances: during an active tone discrimination task and during passive exposure to tones. The aim of this model is to understand the physical structure of the circuit and the input signals that allow for different neural responses to the same tones under different conditions. To read more about this work, see the following paper: Parallel processing by cortical inhibition enables context-dependent behavior
In the second part, selective visual attention is the focus. In particular, the mechanisms that allow for certain visual features to be enhanced across the visual field are recapitulated in a large scale model of the visual system. While modeling of this type doesn’t allow for a direct comparison to data on the neural level, it has the benefit of providing a behavioral output. Thus, this model is used to understand how voluntary shifts in selective visual attention lead to changes in performance on complex visual tasks. To learn more about this work, see this video: Understanding Biological Visual Attention Using Convolutional Neural Networks – CCN 2017 or the associated manuscript on bioRxiv (now published in eLife). The second chapter in this part includes an extension to these models that is meant to make them more biologically-realistic and thus more comparable to data.
Finally, the third part more directly addresses the ability of context to alter the mapping from sensory inputs to behavior. Here, again, task types are changed in blocks. These different task conditions alter the way in which visual stimuli are encoded in prefrontal cortical neurons, which then allows for a more flexible mapping to behavioral outputs. To understand how these encoding changes come to be, a simplified model that includes Hebbian learning is introduced and analyzed in comparison to analysis of the data. To learn more about this work, see the following paper: Hebbian Learning in a Random Network Captures Selectivity Properties of the Prefrontal Cortex
References
Gary Hatfield. Attention in early scientific psychology. Visual attention, 1:3–25, 1998.
Gottfried Wilhelm Leibniz. The principles of philosophy known as monadology. Jonathan
Bennett Edition, 2004.
Robert W Rieber and Kurt Salzinger. Psychology: Theoretical–historical perspectives.
Academic Press, 2013.
Phillip D Tomporowski and Norman R Ellis. Effects of exercise on cognitive processes: A
review. Psychological bulletin, 99(3):338, 1986.
Robert T Wilkinson and M Stretton. Performance after awakening at different times of
night. Psychonomic Science, 23(4):283–285, 1971.
Gregory Belenky, Nancy J Wesensten, David R Thorne, Maria L Thomas, Helen C Sing,
Daniel P Redmond, Michael B Russo, and Thomas J Balkin. Patterns of performance
degradation and restoration during sleep restriction and subsequent recovery: A sleep
dose-response study. Journal of sleep research, 12(1):1–12, 2003.
Bettina M Pause, Alejandra Miranda, Robert Göder, Josef B Aldenhoff, and Roman Ferstl.
Reduced olfactory performance in patients with major depression. Journal of psychiatric
research, 35(5):271–277, 2001.
Charles Spence, Michael ER Nicholls, and Jon Driver. The cost of expecting events in the
wrong sensory modality. Perception & Psychophysics, 63(2):330–336, 2001.
Marisa Carrasco. Visual attention: The past 25 years. Vision research, 51(13):1484–1525,
2011. Daniel J Simons and Christopher F Chabris. Gorillas in our midst: Sustained inattentional
blindness for dynamic events. Perception, 28(9):1059–1074, 1999.
Till R Schneider, Andreas K Engel, and Stefan Debener. Multisensory identification of
natural objects in a two-way crossmodal priming paradigm. Experimental psychology,
55(2):121–132, 2008.
Raymond Y Cho, Leigh E Nystrom, Eric T Brown, Andrew D Jones, Todd S Braver, Philip J
Holmes, and Jonathan D Cohen. Mechanisms underlying dependencies of performance on stimulus history in a two-alternative forced-choice task. Cognitive, Affective, & Behavioral Neuroscience, 2(4):283–299, 2002.
Matthew Lovett-Barron, Aaron S Andalman, William E Allen, Sam Vesuna, Isaac Kauvar,
Vanessa M Burns, and Karl Deisseroth. Ancestral circuits for the coordinated modulation
of brain state. Cell, 2017.
D Dipon Ghosh, Tom Sanders, Soonwook Hong, Li Yan McCurdy, Daniel L Chase, Netta
Cohen, Michael R Koelle, and Michael N Nitabach. Neural architecture of hunger-
dependent multisensory decision making in c. elegans. Neuron, 92(5):1049–1062, 2016.
Susan J Sara and Sebastien Bouret. Orienting and reorienting: the locus coeruleus mediates cognition through arousal. Neuron, 76(1):130–141, 2012.
Sarah Shomstein and Steven Yantis. Control of attention shifts between vision and audition in human cortex. Journal of neuroscience, 24(47):10702–10706, 2004.
Julio C Martinez-Trujillo and Stefan Treue. Feature-based attention increases the selectivity of population responses in primate visual cortex. Current Biology, 14(9):744–751, 2004.
Ying Zhang, Ethan M Meyers, Narcisse P Bichot, Thomas Serre, Tomaso A Poggio, and
Robert Desimone. Object decoding with attention in inferior temporal cortex. Proceedings of the National Academy of Sciences, 108(21):8850–8855, 2011.
Nadine Bazin, Pierre Perruchet, Marie Christine Hardy-Bayle, and André Feline. Context-
dependent information processing in patients with schizophrenia. Schizophrenia research, 45(1):93–101, 2000.
Terry M Parssinen. Popular science and society: the phrenology movement in early victorian britain. Journal of Social History, 8(1):1–20, 1974.
Rodolfo R Llinás. The contribution of santiago ramon y cajal to functional neuroscience.
Nature Reviews Neuroscience, 4(1):77–80, 2003.
Rodney J Douglas and Kevan AC Martin. Neuronal circuits of the neocortex. Annu. Rev.
Neurosci., 27:419–451, 2004.
David H Hubel and Torsten N Wiesel. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. The Journal of physiology, 160(1):106–154, 1962.
Steven Strogatz, the popular applied mathematician and educator, recently tweeted a link to a paper on the question of whether mathematics is something that was invented or discovered:
Is mathematics discovered or invented? That is THE QUESTION. Smart thoughts on it from a leading mathematician: https://t.co/QX2vjWYb1c
— Steven Strogatz (@stevenstrogatz) July 2, 2017
The author of that paper, Barry Mazur, highlights the importance of the subjective experience of doing math in addressing this question. As someone who works in computational neuroscience, I wouldn’t fancy myself a mathematician and so I can’t speak to that subjective experience. However I can say that working in a more applied area still leads one to the question. In fact, it’s something we discuss at length in Unsupervised Thinking Episode 13: The Unreasonable Effectiveness of Mathematics.
It’s been awhile since we recorded that episode and its something that has been on my mind again lately, so I’ve decided to take to the blog to write a quick summary of my thoughts. Mazur also gives in that article a list of do’s and don’ts for people trying to write about this topic. I don’t believe I run afoul of any of those in what follows (certainly not the one about citing fMRI results! yikes), but I suppose there is a chance that I am reducing the question to a non-argument. But here goes:
I think the idea of mathematics as a language is a reasonable place to start. Now when it comes to natural languages, like English or Chinese, I don’t believe there is any argument about whether these languages are invented or discovered. While it may have been a messy, distributed, collective invention through evolution, these languages are ‘invented’ nonetheless. The disorder around the invention of natural languages means that they are not particularly well designed. They are full of ambiguities, redundancies, and exceptions to rules. But they still do a passable job of allowing us to communicate about ourselves and the world.
We cannot, however, do much work with natural languages. That is, we can’t generally take sentences purely as symbols and rearrange them according to abstract rules to make new sentences that are of much value. Therefore, we cannot discover things via natural language. We can use natural language to describe things that we have discovered in the world via other means, but the gap between the language and what it describes is such that its not of much use on its own.
With mathematics, however, that gap is essentially non-existent. Pure mathematicians work with mathematical objects. They use the language to discover things, essentially, about the language itself. This gets trippy however–and leads to these kinds of philosophical questions–when we realize that those symbolic manipulations can be of use to, and lead to discoveries, in the real world. Essentially, math is a rather successful abstraction of the real world in which to work.
But is this ability of math due to the fact that it is a “discovered” entity, or just that it is a well-designed one? There are other languages that are well-designed and can do actual work: computer programming languages. Different programming languages are different ways of abstracting physical changes in hardware and they are successful spaces in which to do many logical tasks. But you’d be hard-pressed to find someone having an argument about whether programming languages are invented or not. We know that humans have come up with programming languages–and indeed many different types–to meet certain requirements of what they wanted to get done and how.
The design of programming languages, however, is in many ways far less constrained than the process that has lead to our current mathematics. An individual programming language needs to be self-consistent and meet certain design requirements decided by the person or people who are making it. It does not have to, for example, be consistent with all other programming languages–languages that have been created for other purposes.
In mathematics, however, we do not allow inconsistencies across different branches, even if those different branches are designed to tackle different problems. It is not the case, for example, that multiplication doesn’t have to be distributive in geometry. I think a strong argument can also be made that the development of mathematics has been influenced heavily by a desire for elegance and simplicity, and by what is useful (and in this way is actually influenced by whether it successfully explains the world). If programming languages were held to a similar constraint, what could have developed is a single form of abstraction that is used to do many different things. We may then have asked if “programming language” (singular) was a discovered entity.
So essentially, what my argument comes down to is the idea that what we call mathematics is a system that has resulted from a large amount of constraints to address a variety of topics. Put this way, it sounds like a solution to an engineering problem, i.e. something we would say is invented. The caveat, however (and where I am potentially turning this into a non-problem), is that what we usually refer to as “discovering” can also be thought of as finding the one, solitary solution to a problem. For example, when scientists “discovered” the structure of DNA, what they really did was find the one solution that was consistent with all the data. If there were more than one solution that were equally consistent, the debate would still be ongoing. So, to say that the mathematical system that we have now is something that was discovered, is to say that we believe that it is the only possible system that could satisfy the constraints. Perhaps that is reasonable, but I find that that formulation is not what most people mean when they talk about math as a discovery. Therefore, I think I (for now) fall on the side of invention.
Meta-caveat: I am in no way wedded to this argument and would love to hear feedback! Especially from mathematicians that have the subjective experience of which Mazur speaks.
Hey All,
Long time no blog! And, yes, as with most grad school bloggers that was initially out of too much work, distraction, and a touch of laziness. But more recently, it’s because I’ve started a new project: podcasting! It’s called Unsupervised Thinking (a play off “unsupervised learning” in machine learning) and it’s a podcast about neuroscience, artificial intelligence, and science more broadly. And since I and my two fellow podcasters are PhD students in computational neuroscience, it’ll have a computational/systems bend.
Our first episode is on Blue Brain/Human Brain Project, which is the large EU-funded project to simulate the brain in a computer. Our next episode will be on brain-computer interface. Check it out by clicking below!
Give us a listen!
