
This is a piece about the present state, and potential future, of fraud in scientific research which I wrote for a Responsible Conduct in Research course taught at Columbia.
There seems to be a trend as of late of prominent scientific researchers been outed for fabrications or falsifications in their data. Diederik Stapel’s extravagant web of invented findings certainly stands out as one of the worst examples, and will probably do long term damage to the field of psychology. But psychology is not alone; other realms of research are suffering from this plague too. For example, the UK government exercised for the first time its right to imprison scientific fraudsters when it sentenced Steven Eaton to 3 months for falsifying data regarding an anti-cancer drug. And accusations of fraud fly frequently from both sides of the debate over climate change. Studies would suggest these misdeeds aren’t limited to just the names that make the news. In an attempt to quantify just how bad scientists are being, journalists sent out a misconduct questionnaire to medical science researchers in Belgium. Four out of the 315 anonymous respondents (1.3%) admitted to flat out fabrication of data and 24% acknowledged seeing such fabrication done by others. Furthermore, analysis of publishing practices has shown a steep increase in the rate of retractions of journal articles since 2005, and investigations suggest that up to 43% of such retractions are due to fraud, with an additional 9.8% coming from plagiarism. It seems clear from both anecdotes and analysis, dishonesty abounds in the research world.
But as with any criminal activity, it is hard to really know how accurate statistics on fraud in scientific publishing can be. Is this wave of retractions and public floggings really a result of an increase in inappropriate behavior, or just an increase in the reporting of it? In other words, are we producing more scientists who are willing to lie, cheat, and steal to get ahead, or more who are willing to sound the alarm on those who do?
Certainly the current financial climate creates an incentive, a need even, for a researcher to stand out from the crowd of their peers like never before. To secure funding from grants, publications highlighting hot-topic research findings are a must. The less money going into science, the more competition there is for grants. So, those research findings must become hotter and more frequent. Furthermore, much of the same “high impact publication”-based criteria is used for determining who gets postdoc positions, assistant professorships, and even tenure. This kind of pressure could, and apparently does, lead some scientists to fake it when they can’t make it.
But while today’s economy may make it easier to justify cheating, today’s technology can make it harder to execute it. We have the ability to automatically search large datasets for the numerical anomalies or repetitions that are hallmarks of fabrication. The contents of an article can be compared to large databases of text to catch a plagiarized paragraph before any human eyes have read it. And the anonymity of the internet provides a way for anyone to report suspicious behavior of even the most senior of scientists without fearing retribution. Thus, it may seem obvious that case after case of fraud is being exposed.
No matter the specific reasons for this recent uptick, misconduct in research is something that always has been and always will be with us. In any competitive situation, with glory and profit on the line, some people will turn to deceit to get ahead. So what can we do reduce the number of wrong-doers to the lowest possible? Well certainly the technological tools mentioned above can help. And some may argue that we should go further, and implement as much surveillance of scientists during their data-collecting as possible. Oversight can prevent the usually solitary scientist from engaging in any “data massaging” that they may have considered when no one was looking. Pre-registration of studies is another tool to ensure experimenters aren’t trying to fiddle with or cover up unsavory data. By stating, before the experiment even begins, what is meant to be tested and how, researchers will be less able to squeeze out whatever p<.05 trends they can find in the data and pretend that’s what they were looking for all along.
While such tools can be effective in preventing the deed of fraud, I think, as a field, we would be better served by preventing the motivation for fraud. This means moving away from a funding system that puts unreasonable weight on flashy results and towards one that favors critical thinking, solid methods, and open data/code sharing. We will need to learn to evaluate our peers by this same criteria as well. Furthermore, our publishing process has to make room for the printing of negative results and replicated studies. The scientist who accidentally stumbles upon an intriguing finding shouldn’t necessarily be praised higher than those who attempt to replicate a result they find suspicious or who have spent years tediously testing hypotheses which turn out to be incorrect. Certainly positive novel findings will continue to be the driving force of any field, and this explains them taking precedence when publishing resources were limited. But with today’s online publishing and quick searches, there is little justification for ignoring other kinds of findings. Additionally, it is now possible for journals to host large datasets and code repositories online along with their journal articles, allowing researchers to get credit for these contributions as well. Technological advancements can be used not only to catch fraud, but to implement the changes that will prevent the motivation for it as well.
Of course, incorporating these achievements will require a more complex means of evaluating scientists for grants and promotions, and this will take time. But it is crucial that we start We need to create a culture that recognizes the importance of a good scientific process and the extreme harm done by introducing dishonesty into it. The hierarchical nature of science, with new studies being built on the backs of old ones, means that one small act of fraud can have far-reaching and potentially irreversible effects on the field. Furthermore, it damages the reputation of scientific research in the public eye, which can lessen confidence and support. People may have been upset to learn of Jonah Lerner’s fraudulent reporting of neuroscience, but such concerns pale in comparison to learning of the fraudulent conducting of neuroscience. While fraud and data manipulation are hardly new problems, there can always be new solutions for combating them. We are lucky to live in an age that allows us the tools to detect such practices when they occur, and also to change the system that encourages them. While it is unlikely that we will ever fully eradicate scientific misconduct, we can hope to create a culture amongst scientist that makes dishonesty less common and that views fabrication as an unthinkable option.
![]() Van Noorden, R. (2011). Science publishing: The trouble with retractions Nature, 478 (7367), 26-28 DOI: 10.1038/478026a
Van Noorden, R. (2011). Science publishing: The trouble with retractions Nature, 478 (7367), 26-28 DOI: 10.1038/478026a
The range of tools used to study the brain is vast. Neuroscientists toss together ideas from genetics, biochemistry, immunology, physics, computer science, medicine and countless other fields when choosing their techniques. We work on animals ranging from barely-visible worms and the common fruit fly to complicated creatures like mice, monkeys, and men. We record from any brain region we can reach, during all kinds of tasks, while the subject is awake or anesthetized, freely moving or fixed, a full animal or merely a slice of brain…and the list goes on. The result is a massive, complex cocktail of neuroscientific information.
Now, I’ve waxed romantic about the benefits of this diversity before. And I still do believe in the power of working in an interdisciplinary field; neuroscientists are creating an impressively vast collection of data points about the brain, and it is exciting to see that collection continuously grow in every direction. But in the interest of honesty, good journalism, and stirring up controversy, I think it’s time we look at the potential problems stemming from Neuroscience’s poly-methodological tendencies. And the heart of the issue, as I see it, is in how we are connecting all those points.
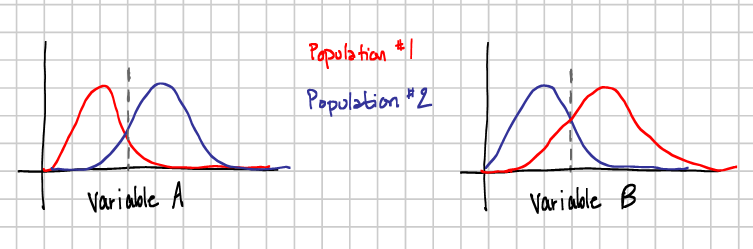
Combining data from the two populations and calculating the mean (dashed grey line) would show no difference between Variable A and Variable B. In actuality, the two variables are anti-correlated in each population.
When we collect data from different animals, in different forms, and under different conditions, what we have is a lot of different datasets. Yet what we seem to be looking for, implicitly or explicitly, are some general theories of how neurons, networks, and brains as a whole work. So, for example, we get some results about the molecular properties needed for neurogenesis in the rat olfactory bulb, and we use these findings to support experiments done in the mouse and vice versa. What we’re assuming is that neurons in these different animals are doing the same task, and using the same means to accomplish it. But the fact is, there are a lot of different ways to accomplish a task, and many different combinations of input that will give you the same output. Combining these data sets as though they’re one could be muddling the message each is trying to send about how its system is working. It’s like trying to learn about a population with bimodally distributed variables by studying their means (see Fig 1). In order to get accurate outcomes, we need self-consistent data. If you use the gravity on the Moon to calculate how much force you need to take off from the Earth, you’re not going to get off the ground.
Not to malign my own kind, but theorists, with their abstract “neural network” models, can actually be some of the worst offenders when it comes to data-muddling. By using average values for cellular and network properties pulled from many corners of the literature, and building networks that aren’t meant to have any specific correlate in the real world, modelers can end up with a simulated Frankenstein: technically impressive, yes, but not truly recreating the whole of any of its parts. This quest for the Platonic neural network—the desire to explain neural function in the abstract—seems, to me, misguided. Rather, even as theorists, we should not be attempting to explain how neurons do what they do—but rather how V1 cells in anesthetized adult cats show contrast invariant tuning, or how GABA interneurons contribute to gamma oscillations in mouse hippocampal slices, and so on. Being precise in determining what our models are trying to be will better fuel how we design and constrain them, and lead to more directly testable hypotheses. The search for what is common to all networks should be saved until we know more of what is specific to each.
Eve Marder at Brandeis University has been something of a crusader for the notion that models should be individualized. She’s taken to running simulations to show how the same behavior can be produced by a vast array of different parameter values. For example, in this PNAS paper, Marder shows that the same bursting firing patterns can be created by different sets of synaptic and membrane conductances (Fig 2). This shows how simply observing a similar phenomenon across different preparations is not enough to assume that the mechanisms producing it are the same. This assumption can lead to problems if, in the pursuit of understanding bursting mechanisms, we measured sodium conductances from the system on the left, and calcium conductances from that on the right. Any resulting model we could create incorporating both these values would be an inaccurate explanation of either system. It’s as though we’re combining the pieces from two different puzzles, and trying to reassemble them as one.
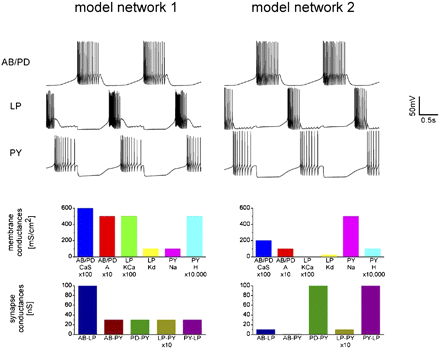
Figure 2. The voltage traces show that the two systems have similar spiking behavior. But it is accomplished with different conductance values.
Now of course most researchers are aware of the potential differences across different preparations, and the fact that one cannot assume that what’s true for the anesthetized rat is true for the behaving one. But these sorts of concerns are usually relegated to a line or two in the introduction or discussion sections. On the whole, there is still the notion that ideas can be borrowed from nearby lines of research and bent to fit into the narrative of the hypothesis at hand. This view is not absurd, of course, and it comes partly from reason, but also from necessity: there’s just some types of data that we can only get from certain preparations. Furthermore, time and resource constraints mean that it is frequently not plausible to run the exact experiment you may want. And on top of the practical reasons for combining data, there is also the fact that evolution supports the notion that molecules and mechanisms would be conserved across brain areas and species. This is, after all, why we feel justified in using animal models to investigate human function and disorder in the first place.
But, like with many things in Neuroscience, we simply can’t know until we know. It is not in our best interest, in the course of trying to understand how neural networks work, to assume that different networks are working in the same way. Certainly frameworks found to be true in specific areas can and should be investigated in others. But we have to be aware of when we are carefully importing ideas and using evidence to support the mixing of data, and when we’re simply throwing together whatever is on hand. Luckily, there are tools for this. Large scale projects like those at the Allen Brain Institute are doing a fantastic job of creating consistent, complete, detailed, and organized datasets of specific animal models. And even for smaller projects, neuroinformatics can help us keep track of what data comes from where, and how similar it is across preparations. Overall, it needn’t be a huge struggle to keep our lines of research straight, but it is important. Because a poorly mixed cocktail of data will just make the whole field dizzy.
![]() Marder, E. (2011). Colloquium Paper: Variability, compensation, and modulation in neurons and circuits Proceedings of the National Academy of Sciences, 108 (Supplement_3), 15542-15548 DOI: 10.1073/pnas.1010674108
Marder, E. (2011). Colloquium Paper: Variability, compensation, and modulation in neurons and circuits Proceedings of the National Academy of Sciences, 108 (Supplement_3), 15542-15548 DOI: 10.1073/pnas.1010674108
Pursuing rewards is a crucial part of survival for any species. The circuitry that tells us to seek out pleasure is what ensures that we find food, drink, and mates. In order to engage in this behavior, we must learn associations between rewards and the stimuli that predict them. That way we can know that our caffeine craving, for example, can be quenched by seeking the siren in a green circle (it’s possible that I do my blog writing at a Starbucks–cuz I’m original like that). Studying this kind of reinforcement learning is big business, and there is still a lot left to find out. But what has been known for some 15 years now is that dopaminergic cells in the midbrain which encode reward value also encode reward expectation. That is, in the ventral tegmental area (VTA), cells increase their firing in response to the delivery of an unexpected reward, such as a sudden drop of juice on a monkey’s tongue. But cells here also fire in response to a reward cue, say a symbol on a screen that the monkey has learned predicts the juice reward. What’s more, after this cue, the arrival of the actual reward causes no change in the firing of these cells unless it is higher or lower than expected. So, these cells are learning to value the promise of a pleasurable stimulus, and signal whether that promise is fulfilled, denied, or exceeded. Suddenly, the sight of the siren is a reward on its own, and getting your coffee is merely neutral.
But the world is rarely just a series of cues and rewards. It’s complex and dynamic: a symbol may predict something positive in one context and punishment in another; reward contingencies can be uncertain or change over time; and with a constant stream of incoming stimuli how do you even figure out what acts as a reward cue in the first place? Luckily, Ethan Bromberg-Martin and Okihide Hikosaka are interested in explaining just these kinds of challenges, and they’ve made a discovery that offers a nice framework on which to build a deeper understanding. In this Neuron paper, Bromberg-Martin and Hikosaka developed a task to test monkeys’ views on information. To start, the monkey was shown one of two symbols, A or B, to which the he had to saccade. After that, one of a set of four different symbols appeared: if A was initially shown then the second symbol would be A1 or A2, and likewise for B. The appearance of A1 always predicted a big water reward, and A2 always predicted a small water reward (which, to greedy monkeys who know a larger reward is possible, is essentially a punishment). But for B1 and B2, the water amount was randomized; these symbols were useless in providing reward information. So, the appearance of A meant that an informative symbol was on its way, whereas B meant something meaningless was coming. Importantly, the amount of reward was equal on average for A and B, it was only the advanced knowledge of the reward that differed.
Recording from those familiar midbrain dopaminergic cells, the authors saw an increase in activity following the appearance of the information-predicting cue A, and a decrease in response to B. These cells then went on to do their normal duty: showing a large spike in response to A1 (the large reward cue), a decrease to A2, and no change in response when these predicted rewards were actually delivered; or, alternatively, little change in response to B1 and B2, and a spike/dip when an unpredictable large/small reward was delivered. What the initial response to A and B shows is that the VTA is responding to the promise of information about reward in the same way is it responds to the promise of a reward or a reward itself. This is further supported by the fact that when monkeys were presented with both A and B and allowed to choose which to saccade to, they overwhelming preferred A—leading them down the path of reward information.
This may seem like a silly preference. Choosing to be informed about the reward size beforehand doesn’t provide a greater reward size or allow the monkey any more control, so why bother valuing the advanced information? The authors put forth the notion that uncertainty is in someway uncomfortable, so the earlier it is resolved the better. But I’m more inclined to believe their second assertion: the informative path (A) is preferred because it provides stable cue-reward associations that can be learned. The process of learning what cue predicts what reward assumes that there are cues that actually do predict reward. So if we want to achieve that goal we have to make sure we’re working in a regime where that base assumption is true—this isn’t the case for uninformative path B. Living in a world of meaningless symbols means all your fancy mental equipment for associating cues and rewards is for naught, and it leaves you with little more than luck when it comes to finding what you need. So there is a clear evolutionary advantage in finding reward in (and thus seeking out) stable cue-reward associations.
But like most good discoveries, this one leaves us with a lot of questions, mainly about how the brain comes to find these stable associations rewarding. We know that for a cue to be associated with a reward, it needs to reliably precede that reward. Then through….well, some process that we’re working out the details of….VTA neurons start firing in response to the cue itself. So presumably in order for the brain to associate a certain cue with reward information, the cue has to reliably precede that information. Here’s where we hit a problem. It is easy enough to understand how the brain is aware that the cue was presented (that’s just a visual stimulus, no problem there), and we can equally as well conceive of how it acknowledges the existence of a reward (again, just a physical stimulus which ends up making VTA cells spike), but how can the brain know that information is present? The information that a cue contains about an upcoming reward isn’t a physical stimulus out there in the world; it’s something contained in the brain itself. If we are to learn to associate an external cue with an internal entity like information, the brain needs to be able to monitor what’s happening inside itself the same way it monitors the outside world.
Luckily, there are possible mechanisms for this, and they fit well with the existing role of VTA cells. Here is the equation the brain seems to be using to make basic reward associations:
visual stimulus + VTA cell firing due to some delayed reward = VTA cell firing to visual stimulus.
But VTA cell firing is VTA cell firing, so we can substitute the second term with the righthand side of the equation and get:
visual stimulus #2 + VTA cell firing due to visual stimulus = VTA cell firing to visual stimulus #2
If pseudomath isn’t your thing: basically, the fact that the brain can learn to treat reward cues as reward means that it can learn to treat cues for reward cues as reward. And cues for cues for reward cues? Maybe, but I wouldn’t bet on it. While they did fire in response to the promise of information signified by cue A, the VTA cells still had their biggest spike increase in response to A1, the cue that signaled a big reward. It seems there’s a limit on how far removed a cue can be from an actual reward. Interestingly, this ability of any kind of metacognition appears restricted to more cognitively complex animals such as primates, and probably contributes to their adaptability as a species. While this kind of study hasn’t been done in rats or mice, my guess is you’d be hard-pressed to find such a preference for information in those lower animals.
Of course these findings leave us with something of a chicken-and-egg problem. Our desire for information is supposed to motivate us to pursue situations with stable cue-reward associations. But we can’t develop that desire until the cue-reward association is already mentally established, so what good is it then? There is also the question of how these results fit into the well-established desire that people (and animals) have for gambling. You’re not going to find a roulette wheel that will tell you where its ball is going to land, or a poker player willing to show you their cards. So what allows us to selectively love risk and uncertainty? Some theories suggest that the possibility for huge payoffs can lead to a miscalculation in expected reward and overpower our better, more rational instincts. But it’s still an area of research in economics as well as neuroscience. Basically, the evidence that reliable information is valued and sought after provides many insights into the process of reinforcement learning, but in order to fully understand its role and consequences, we are going to need more–you guessed it–information.
![]() Bromberg-Martin, E., & Hikosaka, O. (2009). Midbrain Dopamine Neurons Signal Preference for Advance Information about Upcoming Rewards Neuron, 63 (1), 119-126 DOI: 10.1016/j.neuron.2009.06.009
Bromberg-Martin, E., & Hikosaka, O. (2009). Midbrain Dopamine Neurons Signal Preference for Advance Information about Upcoming Rewards Neuron, 63 (1), 119-126 DOI: 10.1016/j.neuron.2009.06.009
Talking with fellow scientists, it would seem that most have a love/hate relationship with the current state of scientific publishing. They dislike the fact that getting a Science or Nature paper seems to be the de facto goal of research these days, but don’t hesitate to pop open the bubbly if they achieve it. This somewhat contradictory attitude is not altogether unreasonable given the current setup. The fate of many a researching career is dependent on getting a paper (or papers) into one of these ‘high impact’ journals. And as illogical as it seems for the ultimate measure of the importance of months of research to be in the hands of a couple of editors and one to three peer reviewers, these are the rules of the game. And if you want to get ahead, you gotta play.
The tides, however, may possibly be changing. Many smaller journals have cropped up recently, focusing on specific areas of research and implementing a more open and accepting review process. PLoS ONE and Frontiers are at the forefront of this. Since the mid-2000s, these journals have been publishing papers based purely on technical merit, rather than some pre-judged notion of importance. This leads to a roughly 70-90% acceptance rate (compared to Nature’s 8% and Science’s <7%), and a much quicker submission-to-print time. It also necessitates a post-publishing assessment of the importance and interest level of each piece of research. PLoS achieves this through article-level metrics related to views, citations, blog coverage, etc. Frontiers offers a similar quantification of interest, and the ability of readers to leave commentary. Basically, these publications recognize the flaws inherent in the pre-publication review system and try to redress them. PLoS says it best themselves:
“Too often a journal’s decision to publish a paper is dominated by what the Editor/s think is interesting and will gain greater readership — both of which are subjective judgments and lead to decisions which are frustrating and delay the publication of your work. PLOS ONE will rigorously peer-review your submissions and publish all papers that are judged to be technically sound. Judgments about the importance of any particular paper are then made after publication by the readership (who are the most qualified to determine what is of interest to them).”
So we have the framework for a new type of review and publication process. But such a tool is only helpful to the extent that we utilize it. Namely, we need to start recognizing and rewarding the researchers who publish good work in these journals. This also implies putting less emphasis on the old giants, Nature and Science. But how will these behemoth establishments respond to the revolution? Well, we may soon find out. NPG, the publishing company behind Nature has recently announced a majority investment in Frontiers. The press release stresses that Frontiers will continue to operate under its own policies, but describes how Frontiers and Nature will interact to expand the number of open access articles available on both sides. Interestingly, the release also states that “Frontiers and NPG will also be working together on innovations in open science tools, networking, and publication processes. “ A quote from Dr. Phillip Campbell, Editor-in-Chief of Nature is even more revealing:
“Referees and handling editors are named on published papers, which is very unusual in the life sciences community. Nature has experimented with open peer review in the past, and we continue to be interested in researchers’ attitudes. Frontiers also encourages non-peer reviewed open access commentary, empowering the academic community to openly discuss some of the grand challenges of science with a wide audience.”
Putting (perhaps somewhat naively) conspiracies of an evil corporate takeover aside, could this move mean that the revolution will be a peaceful one? That Nature sees the writing on the wall and is choosing to adapt rather than perish?
If so, what would a post-pre-publication-review world look like? Clearly if some sort of crowdsourcing is going to be used to determine a researcher’s merit, it will have to be reliable and standardized. For example, looking at the number of citations per article views/downloads is helpful in determining if an article is merely well-promoted, but not necessarily helpful to the community—or vice-versa. And more detailed information can be gathered about how the article is cited: are its results being refuted or supported? is it one in a list of many background citations or the very basis of a new project? Furthermore, whatever pre-publishing review the article has been submitted to (for technical merit, clarity, etc) should be posted alongside the article along with reviewer names. The post-publishing commentary will also need to be formalized (with rankings on different aspects of the research: originality, clarity, impact, etc) and fully open (no anon trolls or self-upvoting allowed). Making participation in the online community a mandatory part of getting a paper published can ensure that papers don’t go un-reviewed (the very new journal PeerJ uses something like this). If sites like Wikipedia and Quora have taught us anything (aside from how everything your mother warned you about is wrong), it’s that people don’t mind sharing their knowledge, especially if they get to do it in their own way/time. And since the whole process will be open, any “you scratch my back, I’ll scratch yours” behavior will be noticeable to the masses. The practices of Frontiers and PLoS are steps in the right direction, but their article metrics will need to be richer and more reliable if they are to take the place of big-name journal publications for a measure of research success.
Some people feel that appropriate post-publishing review makes any role of a journal unnecessary. Everyone could simply post their papers to an e-print service like arXiv, as many in the physical sciences do, and never submit to anywhere officially. Personally, I still see a role for journals—not in placing a stamp of approval on work, but in hosting papers and aggregating and promoting research of a specific kind. I enjoy having the list of Frontiers in Neuroscience articles delivered to my inbox for my perusal. And I like having some notion of where to go if I need information from outside my field. And as datasets become larger and figures more interactive, self-publishing and hosting will become more burdensome. Furthermore, there’s the simple fact that having an outsider set of eye’s proofread your paper and provide feedback before widely distributing it is rarely a bad thing.
But what then is left of the big guns, Science and Nature? They’ve never claimed a role in aggregating papers for specific sub-fields or providing lots of detailed information—quite the opposite, in fact. Science’s mission is to:
“to publish those papers that are most influential in their fields or across fields and that will significantly advance scientific understanding. Selected papers should present novel and broadly important data, syntheses, or concepts. They should merit the recognition by the scientific community and general public provided by publication in Science, beyond that provided by specialty journals.” [emphasis added].
Nature expresses a similar desire for work “of interest to an interdisciplinary readership.” And given that Science and Nature papers have some of the strictest length limits, they’re clearly not interested in extensive data analysis. They want results that are short, sweet and pack a big punch for any reader. The problem is that this isn’t usually how research works. Any strong, concise story was built on years of messy smaller studies, false starts, and negative results—most of which are kept from the rest of the research community while the researcher strives to make everything fall in place for a proper article submission. But in a world of minimal review, any progress (or confirmation of previous results, for that matter) can be shared. Then, rather than let a handful of reviewers (n=3? come on, that only works for monkey research) try to predict the importance of the work, time and the community itself will let it be known. Nature and Science can still achieve their goals of distributing important work across disciplines, but they can do it once the importance has been established, by asking researchers of good work to write a review encapsulating their recent breakthroughs. That way, getting a piece in Nature and Science remains prestigious, and also merited. Yes this means a delay between the work and publication in these journals, but if importance really is their criteria, this delay is necessary (has any scientist gotten the Nobel Prize six months after their discovery?). Furthermore, it’ll stop the cycle of self-fulfilling research importance whereby Nature or Science deems a topic important, prints about it, and thus makes it more important. This cycle is especially potent given the fact that the mainstream media frequently looks to Science and Nature for current trends and findings, and thus their power goes beyond just the research community. In a system where their publications were proven to be important, this promotion to the press would be warranted.
The goals of the big name journals are admirable: trying to acknowledge important work and spread it in a readable fashion to a broader audience. But their ways of going about it are antiquated. There was a time when getting a couple of the current thinkers in a field together to decide the merit of a piece of work was the only reasonable technique, but those days are gone. The data-collecting power of web-based tools is immense and their application is incredibly apropos here. We have the technology; we can rebuild the review system. NPG’s involvement with Frontiers offers hope (to the optimistic) that these ideas will come to fruition. We already know that Frontiers supports them. We just need the community at large to follow suit in order to give validity to these measures.
Since the vague reference to it in the State of the Union and the subsequent report by the New York Times, the neuro-sphere has been abuzz with debate recently over the proposed Brain Activity Map (BAM) project put forth by the Obama administration. While the details have not been formally announced yet, it is generally agreed upon that the project will be a ten-year, 3 billion-dollar initiative organized primarily by the Office of Science and Technology Policy with participation from the NSF, NIH, and DoD along with some private institutions. The goal is to coordinate a large-scale effort to create a full mapping of brain activity, down to the level of individual cell firing. It has been likened to the Human Genome project, both in size and in potential to change our understanding of ourselves.
But, while optimism regarding the power of ambitious scientific endeavors shouldn’t be discouraged (I’m no enemy to “Big Science”), it is important to ask what we really expect to get out of this venture. Let’s start with the scientific goals themselves. What is actually meant by “mapping brain activity”? The idea for this project is supposedly based on a paper published in Neuron in June (which itself stemmed from a meeting hosted by the Kavli Foundation). In it, the authors express the desire to capture every action potential from every cell in a circuit, over timescales “on which behavioral output, or mental states, occur.” This proposal is very well-intentioned, but equally vague. Yes, most any neuroscientist would love to know the activity of every cell at all times. And by focusing on activity we know that incidental features like neurotransmitters used or cell size and shape won’t be of much importance. But when enlisting hordes of neuroscientists to dedicate themselves to a collective effort, desired outcomes need to be made explicit. What, for example, is meant by a circuit? The authors give examples suggesting that anatomical divisions would be the defining lines (like focusing on the medulla of the fly). But given the importance of inter-area connections for computations, anatomical divisions aren’t always the best option for identifying and understanding a circuit with a specific purpose. Next, we have the notion of collecting data over the course of behavioral outputs or mental states. Putting aside the blatant opacity of these terms, there remains the question of what kind of ‘mental states’ and ‘behavioral outputs’ we want to measure. Is the desire to get a snapshot of the brain in some kind of ‘null state’ and then compare that to activity patterns that occur during specific tasks? But which tasks? And how many? Furthermore, the higher the complexity of the species and the task at hand, the more likely there are to be individual differences in the activity maps across animals. Whether or not taking the average appropriately captures the function of individual circuits is debatable. Finally, even the conceptually simple goal of recording every action potential is open to interpretation. Do we want actual waveforms? Most people consider spike times to be the bread and butter of any activity measure, but that still leaves open the question of how much temporal precision we desire. All of these seemingly minor details can have a large impact on experimental design and technique.
Assuming, however, that all these details are sorted out (as they must be), we’re then left grappling with our expectations over what this data will mean. A quick poll of the media might have you believe that a BAM is akin to a mental illness panacea, a blueprint for our cyborg future, and the answer to whether or not we have a soul. Most in the field are, thankfully, less starry-eyed. To us, a record of every cell’s activity will result in…a lot of data, and thus, the need to develop tools to understand that data. This will boost the demand for theoretical models that attempt to account for how the dynamics of neural activity can implement information processing. As the dataset of activity patterns increases, the more constrained, and presumably more accurate, these models will become. Ideally, this will eventually lead to an understanding of the mechanisms by which brains process inputs and produce outputs. Acknowledging this more sober goal as the true potential outcome of the BAM project, some neuroscientists feel that the loftier promises made by those outside the field (and even some within) are dishonest and, in a sense, manipulative. The fact is the acquisition of this data does not guarantee our understanding of it, and our understanding of it does not ensure the immediate production of tangible benefits to society. To make a direct link between this project and a cure for Parkinson’s or the advent of downloadable memories is fraudulent. These are not the immediate goals. But science is of course a cumulative process, and the more we understand about the brain the better equipped we are to pursue avenues to treat and enhance it. The creation of a BAM is, I believe, a good approach to advance that understanding and thus has the potential to be very beneficial.

Transparency is a non-trivial skill when attempting to image the whole brain.
But even if the anticipated long-term and philosophical results of Obama administration’s project are hazy, there are some more concrete benefits expected to come out of it: mainly, advances in all kinds of technologies. The notion that the government sinking large sums of money into a scientific endeavor leads to economic and technological progress is well-agreed upon and fairly well-supported. And the nature of this project indicates it could have an effect on a wide variety of fields. Google, Qualcomm, and Microsoft have already been cited as potential partners in the effort to manage the astronomical amounts of data this work would create. The NYT article cites an explicit desire to invest in nanoscience research, potentially as a new avenue for creating voltage indicators. Optics is also a huge component to this task, so advances in microscopy are a necessity. Furthermore, techniques currently in use tend to utilize animal-specific properties that make them not translatable to other species (such as the fact that zebrafish can be made to be transparent and we, currently, cannot). So if this really is to be a human brain activity map (as the government seems to suggest) a whole new level of non-invasive imaging techniques will need to be devised. Another potential solution to that problem, as the Neuron article suggests, requires investment in the development of synthetic biological markers that may not rely on imaging in order to record neural activity. In another vein, the article also makes a point of defending the notion that all data obtained should be made publicly available. This project might then have the added benefit of advancing the open access cause and spurring new technologies for public data sharing.
Overall, it is important to take a realistic view on what to expect from a project of this magnitude and ambition. It can be tempting, as it frequently is with studies of the brain especially, to overstate or romanticize the potential results and implications. On the whole this benefits no one. What’s important is finding the right level of realistic optimism that recognizes the importance of the work, even without attaching to it the more grandiose expectations. Furthermore, a safe bet can be made on the fact that if this project comes to fruition, the work itself will have some immediate tangential benefits (economic and technological) and produce unforeseeable ripples in many fields for years to come.
![]() A. Paul Alivisatos, Miyoung Chun, George M. Church, Ralph J. Greenspan, Michael L. Roukes, Rafael Yuste (2012). The Brain Activity Map Project and the Challenge of Functional Connectomics Neuron
A. Paul Alivisatos, Miyoung Chun, George M. Church, Ralph J. Greenspan, Michael L. Roukes, Rafael Yuste (2012). The Brain Activity Map Project and the Challenge of Functional Connectomics Neuron
Recently, I was charged with giving a presentation to a group of high schoolers preparing for the Brain Bee on the topic of computational approaches to neuroscience. Of course, in order to reach my goal of informing and exciting these kids about the subject, I had to start with the very basic questions of ‘what’ and ‘why.’ It seems like this task should be simple enough for someone in the field. But what I’ve discovered–in the course of doing computational work and in trying to explain my work to others–is that neither answer is entirely straightforward. There is the general notion that computational neuroscience is an approach to studying the brain that uses mathematics and computational modeling. But as far what exactly falls under that umbrella and why it’s done, we are far from having a consensus. Ask anyone off the street and they’re probably unaware that computational neuroscience exists. Scientists and even other neuroscientists are more likely to have encountered it but don’t necessarily understand the motivation for it or see the benefits. And even the people doing computational work will come up with different definitions and claim different end goals.
So to add to that occasionally disharmonious chorus of voices, I’d like to present my own explanation of what computational neuroscience is and why we do it. And while the topic itself may be complicated and convoluted, my description, I hope, will not be. Basically, I want to stress that computational neuroscience is merely a continuation of the normal observation- and model-based approach to research that explains what so many other scientists do. It needn’t be more difficult to justify or explain than any other methodology. Its potential to be viewed as something qualitatively different comes from the complex and relatively abstract nature of the tools it uses. But the choice of those tools is necessitated simply by the complex and relatively abstract nature of what they’re being applied to, the brain. At its core, however, computational neuroscience follows the same basic steps common to any scientific practice: making observations, combining observations into a conceptual framework, and using that framework to explain or predict further observations.
That was, after all, the process used by two of the founding members of computational neuroscience, Hodgkin and Huxley. They used a large set of data about membrane voltage, ion concentrations, conductances, and currents associated with the squid giant axon (much of which they impressively collected themselves). They integrated the patterns that they found in this data into a model of a neural membrane, which they laid out as a set of coupled mathematical equations each representing different aspects of the membrane. Given the right parameters, the solutions to these equations matched what was seen experimentally. If a given amount of current injection made the squid giant axon spike, then you could put in the same amount of current as a parameter in the equations and you would see the value of the membrane potential respond the same way. Thus, this set of equations served (and still does serve) as framework for understanding and predicting a neuron’s response under different conditions. With some understanding of what each of the parameters in the equations is meant to represent physically, this model has great explanatory power (as defined here) and provides some intuition about what is really happening at the membrane. By providing a unified explanation for a set of observations, the Hodgkin-Huxley model does exactly what any good scientific theory should do.
It may seem, perhaps, that the the actual mathematical model is superfluous. If Hodgkin and Huxley knew enough to know how to build the model, and if knowledge of the what the model means has to be applied in order to understand its results, then what is the mathematical model contributing? Two things that math is great for: precision and the ability to handle complexity. If we wanted to, say, predict what happens when we throw a ball up in the air, we could use a very simple conceptual model that says the force of gravity will counteract the throwing force, causing the ball to go up, pause at its peak height, and come back down. So we could use this to predict that more force would allow the ball to evade gravity’s pull for longer. But how much longer? Without using previous experiments to quantify the force of gravity and formalize its effect in the form of an equation, we can’t know. So, building mathematical models allows for more precise predictions. Furthermore, what if we wanted to perform this experiment on a windy day, or put a jetpack on the ball, or see what happens in the presence of second planet’s gravitational pull, or all of the above? The more complicated a system is, and the more its component parts counteract each other, the less likely it is that simply “thinking through” a conceptual model will provide the correct results. This is especially true in the nervous system, where all the moving parts can interact with each other in frequently nonlinear ways, providing some unintuitive results. For example, the Hodgkin-Huxley model demonstrates a peculiar ability of some neurons: the post-inhibitory rebound spike. This is when a cell fires (counterintuitively) after the application of an inhibitory input. It occurs due to the reliance of the sodium channels on two different mechanisms for opening, and the fact that these mechanisms respond to voltage changes on a different timescale. This phenomenon would not be understandable without a model that had the appropriate complexity (multiple sodium channel gates) and precision (exact timescales for each). So, building models is not a fundamentally different approach to science; we do it every time we infer some kind of functional explanation for a process. However, formalizing our models in terms of mathematics allows us to see and understand more minute and complex processes.

A Hodgkin-Huxley simulation showing post-inhibitory rebound spiking.
Additionally, the act of building explicit models requires that we investigate which properties are worth modeling and in what level of detail. In this way, we discover what is crucial for a given phenomenon to a occur and what is not. In many regards, this can be considered a main goal of computational modeling. The Human Brain Project seeks to use its 1 billion Euro prize to model the human brain in the highest level of detail and complexity possible. But, as many detractors point out, having a complete model of the brain in equation form does little to decrease the mystery of it. The value of this simulation, I would say, then comes in seeing what parameters can be fudged, tweaked, or removed entirely and still allow the proper behavior to occur. Basically, we want to build it to learn how to break it. Furthermore, as with any hypothesis testing, the real opportunity comes when the predictions from this large-scale model don’t line up with reality. This lets us hunt for the crucial aspect that’s missing.
Computational neuroscience, however, is more than just modeling of neurons. But, in the same way that computational models are just an extension of the normal scientific practice of modeling, the rest of computational neuroscience is just an extension of other regular scientific practices as well. It is the nature of what we’re studying, however, that makes this not entirely obvious. Say you want to investigate the function of the liver. Knowing it has some role in the processing of toxins, it makes sense to measure toxin levels in the blood, presence of enzymes in the liver, etc when trying to understand how it works. But the brain is known to have a role in processing information. So we have to try, as best we can, to quantify and measure that. This leads to some abstract concepts about how much information the activity of a population of cells contains and how that information is being transferred between populations. The fact that we don’t even know exactly what feature of the neural activity contains this information does not make the process any simpler. But the basic notion of desiring to quantify an important aspect of your system of interest is in no way novel. And much of computational neuroscience is simply trying to do that.
So, the honest answer to the question of what computational neuroscience is is that it is the study of the brain. We do it because we want to know how the brain works, or doesn’t work. But, as a hugely complex system with a myriad of functions (some of which are ill- or undefined), the brain is not an easy study. If we want to make progress we need to choose our tools accordingly. So we end up with a variety of approaches that rely heavily on computations as a means of managing the complexity and measuring the function. But this does not necessarily mean that computational neuroscientists belong to a separate school of thought. The fact that we can use computers and computations to understand the brain does not mean that the brain works like a computer. We merely recognize the limitations inherent in studying the brain, and we are willing to take help wherever we can get it in order to work around them. In this way, computational approaches to neuroscience simply emerge as potential solutions to the very complicated problem of understanding the brain.
![]() Kaplan, D. (2011). Explanation and description in computational neuroscience Synthese, 183 (3), 339-373 DOI: 10.1007/s11229-011-9970-0
Kaplan, D. (2011). Explanation and description in computational neuroscience Synthese, 183 (3), 339-373 DOI: 10.1007/s11229-011-9970-0
Hey do you know about the Dana Foundation? It’s a New York-based philanthropic organization dedicated to funding brain research, education, and outreach. They organize fun things like global Brain Awareness Week and online brain resources for kids. They also host a blog aimed at describing aspects of neuroscience to the general public, and today marks the first in a series of three monthly guest posts I’ll be doing for them!
The topic I chose for this series is neuroplasticity. Plasticity, the brain’s ability to adapt and change, is an area of huge research. Developmentally, there are questions about what inputs are required (and at what times) in order to properly prune and shape connections in the early brain. On the molecular scale, we want to know what proteins are involved in signaling and inducing changes in synapses. At the systems level, how the relative timing of spikes from different cells affects synaptic weights is being investigated. On the more practical side, translational workers want to harness the beneficial aspects of the brain’s response to injury while minimizing the negative ones. Clearly the topic of plasticity provides a depth and breadth of questions for neuroscientists–and thus plenty of material for a blog.
But beyond simply stressing the variety of ways in which the brain is plastic, I’d like to go a step further. I would say that plasticity is the brain. Changing connections and synaptic weights isn’t merely something the brain can do when necessary; it is the permanent state of affairs. And thankfully so. Plasticity on some level is required in order to do many of the things we consider crucial brain functions –memory, learning, sensory information processing, motor skill development, and even personality. The brain is always reorganizing itself, synapse by synapse, in order to best process its inputs and create appropriate outputs. This kind of adaptive behavior keeps us alive–say, by creating a memory of a food that once made us sick so that we know to avoid it in the future. And makes us good at what we do–changes in motor cortex, for example, are why practice makes perfect in many physical activities. There is no underestimating the power, importance, or complexity of neuroplasticity.
In order to cover all these majestic aspects of plasticity, I’ve divided the posts into the following topics (links will be added as they’re available):
–Developmental Plasticity and the Effect of Disorders. How the brain responds to a lack of input during development, and to a disorder that impairs plasticity itself.
–Plasticity in Response to Injury–a Blessing and a Curse. The brain’s attempt to fix itself after stroke, and some weird effects of losing a limb.
–Short-term Plasticity and Everyday Brain Changes. Changing enviornmental demands call for quick and helpful changes in the brain.
Enjoy!
All research methodologies have their challenges. Molecular markers are finicky. Designing human studies is fraught with red tape. And getting neural cultures to grow can seem to require as much luck as skill. But for those of us involved in animal-based research, there is an extra dimension of difficulty: the ethical one. No matter how important the research, performing experiments on animals can stir up some conflicted feelings on the morality of such a method. This only intensifies when studying the brain, the very seat of what these animals are and how (or how much) they think and feel. Even the staunchest believer in the rightness of animal research still has to contend with the fact that a decent portion of society finds what they do unethical. It is not a trivial issue and shouldn’t be treated as such.
But, like with our use of animals for food, clothing, and a variety of other needs, experimenting on animals dates back millennia. The first recorded cases came from ancient Greece and have continued ever since. Now while historical precedent is not sufficient evidence of ethicality, the history of animal testing does allow us to recognize the great advances that can come from it. Nearly all of our tools of modern medicine, our knowledge about learning and behavior and our standards for food safety and nutrition would be gone with the absence of animal research. I certainly wouldn’t be writing a blog called Neurdiness, because Neuroscience wouldn’t exist as a field. It is clear that animal testing has proven crucial to the advancement of our society, and perhaps even to its very survival. And that value cannot be overlooked or underappreciated when having a discussion about morality.
So, we seem to come to an impasse. The instinctive distaste for replacing freedom with suffering in animals is pitted against the knowledge that this practice will prevent suffering in humans. And how to equate the two is unclear. Is an effective treatment for Alzheimer’s or Parkinson’s worth the lives of countless rats, mice, and pigs? What about the potential for such a treatment? Does our desire to understand higher cognitive functions—which may not lead directly to medical advances, but could change our notions of who we are and how we think—justify experiments on non-human primates, the only animals from which we can glean such information? Beliefs exist at either extreme: so-called “abolitionists” claim no exploitation of animals is ever justified, while at the other end is the feeling that animals lack moral standing and their needs are thus subordinate to those of humans.
Personally, I view the use of animals in research as something of a necessary evil. For the majority of human history, people felt free to capture, kill, or enslave animals for a variety of purposes. For food, for powering agricultural tools, for transportation, for materials. We’ve since outgrown the need to use animals for many of these things, but before modern technology their use seemed perfectly justified and even required. Indeed, civilization would be nothing like it is now without our willingness to utilize animals. The present state of neuroscience research is something like that of early humans. I’m vegan because the state of modern food production and distribution means I can be healthy without harming animals. But I’m an animal researcher because in the present state of Neuroscience I know we cannot progress the field without them. We don’t yet have the technology to free ourselves of a dependence on animals, and our ability to reach that point requires their continued use.
Working in this moral gray zone leaves many neuroscientists feeling uneasy about discussing their methodology with the general public. Of course divulging any specific details about animal suppliers or where the animals are housed, etc. is dangerous due to the risk of it falling into the wrong hands, but speaking openly about engaging in animal research should not be outside the realm of comfort of a researcher. The right balance of ensuring safety while still defending your position is clearly a hard one to strike (as the results of this Nature survey suggest). But the voices of scientists involved in the work is crucially needed in the public debate and thus the proper practices need to be established by research institutions so as to disallow the prevention of this participation by fear.
Of course the best way to encourage support for the use of animals in your research is to ensure that you’re doing good science. To most people, animal research is acceptable on the grounds that its providing a significant benefit and experimenters need to keep this mandate in mind. Importantly, doing good science also means adhering to the guidelines for proper care and treatment of laboratory animals. Those concerned about the treatment of animals in labs would be happy to know that there are a plethora of agencies overlooking the design of animal experiments, how animals are housed, and ensuring that the least amount of pain is inflicted as possible (an extensive list of related resources can be found here). An important tenet is the “three R’s” of animal testing. This framework, first put forward by Russell and Burch in 1959, urges reduction (use only the amount of animals needed to significantly verify a finding, and use them wisely and carefully so as to reduce unneeded waste), refinement (use the most humane housing, anesthetic, and experimental techniques available, avoiding invasive and painful procedures if possible), and replacement (seek alternatives to animal use whenever possible; options include culturing tissues in a dish, computational modeling, and the use of lower animals or plant life). Adhering to such rules and guidelines from over-seeing agencies is important for both the continued operation of a lab as well the maintaining a good public perception. Furthermore, the proper treatment of lab animals is not merely a means of appeasing animal rights activists; it is crucial for attaining accurate results, especially in neuroscience. It is known that physical and psychological stress can have huge impacts on the brain and an unhealthy animal is likely to produce unreliable results. Additionally, keeping in line with proper practices can reduce the unease that a researcher may feel about their work with animals.
In the realm of neuroscience, animal research is, in no uncertain terms, a necessity. But at the same time, we are making strides in the implementation of the three R’s, specifically with replacement. The ability to grow neural cultures is widely used when appropriate. Realizing the potential of lower animals to answer questions normally posed to higher ones is also a promising trend. For instance, social behavior in flies and decision-making in rodents are being explored to a greater extent. Computational modeling is also becoming ever more utilized, and while it is far from fully replacing an animal, it can at least predict which experiments have the most potential to be of use, thus reducing wasteful animal use And with time, and the refinement of all these techniques, animals will continue to be used more wisely and with less frequency. So, if researchers don’t become too myopic or complacent, and continue to view their work in the larger ethical context, designing experiments to reduce moral dilemmas, then we can progress in a way that is both humane and fruitful.
![]()
Editors (2011). Animal rights and wrongs Nature, 470 (7335), 435-435 DOI: 10.1038/470435a
Neuroanatomy can happen at many scales. At the highest end, we can ask if certain areas of the brain have connections between them: for example, does the lateral geniculate nucleus (LGN) send projections to primary visual cortex? (hint: yes). Through electrical stimulation and tract-tracing methods, we’ve gotten pretty good at finding this out. We can then look at connections within these areas: which layers of visual cortex connect to each other? Cell-staining and microscopy make this investigation possible. And we can even go further and try to learn about what kind of connections exist within a single layer of cortex (an area that is only fractions of a millimeter thick). Advanced, automated imaging techniques have allowed much progress here. Not only that, we can even look across scales by investigating, for example, which layer of LGN sends connections to which layer of visual cortex. Importantly, the tight relationship between structure and function in the brain means that learning about all these connections provides functional insights in addition to purely anatomical ones.
Now, taking this connectivity quest to its logical extreme, the most we could ask to know is every connection made by every cell in the brain. This information is called the connectome, and it has been causing quite a buzz recently in the neuro-world. What that level of detail could tell us about how the brain computes and how it differs across species and individuals is an area of hot debate. Some people feel the effort to investigate the connectome is a waste of resources, and useless in any case because a single network with constant connectivity can still show vastly different behavior under different conditions (inputs, modulators, etc.). Others feel that much information about a network and its functions is stored in how cells connect to each other. The connectome’s most prominent proponent, Sebastian Seung has almost religious-like zeal for the connectome as the be all and end all in determining who we are.

For the imaging approach, programs like NeuroTrace automatically scan layers of EM images trying to trace neuronal projections.
But if Seung’s mantra of “we are our connectome” is true, then the vast majority of us are going through a major identity crisis. The fact is, there is only one creature for which we have deciphered the connectome: C. elegans. The 7000 synapses between the 302 neurons of this little worm took over 50 person-years to obtain using available imaging techniques. Advances in automated analysis of electron microscopy data are occurring rapidly and can speed up and simplify this process. But scaling this up to, say, a mouse brain (~100 billion synapses) or a human brain (~100 trillion synapses) still seems pretty impractical. Our desire to know the connectome is nowhere near our ability to obtain it.
Enter Anthony Zador, a Cold Spring Harbor researcher with a different approach. His recent paper outlines the delightfully acronymed BOINC (barcoding of individual neuronal connections) method of seeing synapses. Actually, the value of BOINC is in the fact that it takes the “seeing” out of the process. Rather than relying on imaging methods to determine the existence of a synapse, BOINC harnesses the power of genetic sequencing. As the paper points out, DNA sequencing speeds have been increasing nearly as quickly as the prices have been dropping. This powerful combination makes it ideal for such an immensely large project as connectome mapping.
So how does it work? As the name suggests, the process requires each neuron be artificially tagged with its own “barcode”, or sequence of nucleotides. Hosting these barcodes in specific types of viral vectors inside the neuron can allow them to be transferred via synapses to other neurons. Thus, a single neuron will contain its own barcode as well as the barcodes of all the neurons with which it synapses. Next, these barcode sequences will need to be joined inside the cell so that their association can be made known later via sequencing. So, if in the process of sequencing you come across a chunk of DNA with cell A’s unique nucleotide sequence followed by cell X’s unique nucleotide sequence, then you can infer that there’s a connection between cell A and cell X. Do this for all the DNA chunks, get all the connections, and you’ve made yourself a connectome. (Fittingly, the word ‘connectome’ was actually inspired by ‘genome.’ This method should’ve been obvious!).
A schematic of the new approach (BOINC)
Now of course this idea is only in its very early stages. The exact implementation is yet to be determined and plenty of questions about the specifics already abound. To start, giving each neuron a unique DNA label is not a trivial problem. The authors suggest a similar method to the combinatorial one used in creating all the different fluorescent colors for Brainbow, but replacing the florophores with DNA sequences. The next stage, the act of transferring the barcodes across synapses, is luckily not as complicated as it may seem. Viruses specialize in spreading themselves, and rabies and pseudorabies viruses have been used in conjunction with dyes and other markers to trace neural connections for years. This method has its difficulties of course, such as ensuring that the barcode-carrying virus stops transporting itself once it reaches the post-synaptic cell (lest it replicate and invade all cells, giving a lot of false positives). And once the synapse-jumping is accomplished, there is the matter of getting the barcodes to join together in the right way to ensure that which cell is pre- and which is post-synaptic remains decipherable.
And even if all these specifics are successfully tackled, the method itself has its limitations. Essentially what it provides is a connectivity matrix, a list of cells which are defined solely by their connections. We can’t say much else about the type of cells (their location, the neurotransmitter they use), the type of synapse (excitatory v. inhibitory, it’s location on the post-synaptic cell, the morphology), or activity levels. All these aspects are potentially important to our understanding of neuronal wiring. But that’s no reason to dismiss BOINC. The current methodology also has its limiatations and if BOINC works it will be a vast improvement in terms of output rates. It also has the potential to be combined with other traditional techniques to investigate the above properties, yielding a far more complete picture than we have right now.
Overall, we don’t know how important knowing the connectome is for our understanding of average brain function or differences amongst individuals. But making claims about its role when we know so little about it is illogical. Even “anti-connectomists” should recognize that getting results which validate their dismissal of such fine-level anatomical analysis requires that we have the fine-level anatomy to test in the first place. Basically, when it comes to the connectome, we don’t know enough to say that we don’t need to know it. Furthermore, the sequencing approach promises a smaller time and money commitment, quieting those who worry about the resources going into connectomism. So breakthroughs in approaches like this should be applauded by all, both for their potential to advance the field and for encouraging others to think a little outside of their methodological box.
![]()
Zador, A., Dubnau, J., Oyibo, H., Zhan, H., Cao, G., & Peikon, I. (2012). Sequencing the Connectome PLoS Biology, 10 (10) DOI: 10.1371/journal.pbio.1001411
Earning a PhD is a lot like having a baby. It’s time-consuming, messy, and can cause a lot of sleepless nights. Importantly, it also doesn’t come with an instruction manual. Grad students start their program with a list of course requirements and the charge to “do research.” But what that actually means and how to do it well is conveniently, and possibly intentionally, left out. Essentially, the process of earning your PhD is meant to teach you how to do research. But, in the spirit of New Year’s resolutions, I think it would be helpful to offer some more concrete tips that can make the process a little smoother. Now, since I have a whole one semester of grad school under my belt (hold your applause), I may not be in the best position to give advice. I am, however, perfectly-suited for pestering older grad students and PhD holders for their words of wisdom and scouring the internet for help (by the internet I mostly mean Quora. Do you Quora? I Quora. If you don’t Quora, you should really Quora). So I’ve collected some of the main themes agreed to be necessary for a successful PhD by the people who have done them and present them to you here (in no particular order):
Organize. Your notes, your lab book, your time. Organization is a fuel for productivity. It doesn’t matter if you spend all night running experiments if your lab book is so messy that the next morning you don’t even know what variables you were manipulating. And there’s not much point in frantically taking notes during a lecture or while reading a paper if you have no meaningful way of referencing them later. Also, in grad school, just like in life, time is your most valuable resource so you want to make sure you’re spending it wisely.
Luckily, in this digital age we live in, there are plenty of tools to help you organize just about everything. I like Mendeley for papers, because it can actually save notations you add, is accessible from anywhere, and makes it super easy to compile citations. Endnote and Citeyoulike have been highly-recommended for paper and note-organizing as well. I’m a big fan of toodledo or other online todo lists sites for keeping track of tasks and nothing beats good old Google calendar for a visual representation of your time. Of course, all these services only work to the extent that you use them and use them well. So remember to actually import your papers to Mendeley, categorize your notes appropriately, and set realistic time tables for your tasks. And don’t get too carried away with all the technology, or you may need to get a service to organize your organizational services.
Stay Healthy. Mentally and physically. It is quite possible for graduate students to get so wrapped up in their work to the point of neglecting important things like eating, sleeping, and moving. While this dedication seems potentially beneficial, the fact is that such habits are not sustainable and will, sooner or later, catch up to you and your PhD progress. You are unlikely to think up any significant breakthroughs when stressed, hungover, and/or depressed. If it helps, think of yourself as a piece of expensive lab equipment that needs proper care and maintenance to produce good results.
Having a few hobbies completely unrelated to your work can keep you grounded, sane, and in-shape. Something like team sports or dance lessons have the dual benefit of physical exercise, a well-known stress reliever, and some (probably much-needed) social interaction with non-scientists. Engaging in external interests can also spark your creativity within your own line of work and guarantees that your happiness isn’t completely tied to the current state of your research. Maybe you haven’t gotten an experiment to work in a month, but you did learn how to whittle an awesome spoon and planned the perfect birthday dinner for your significant other (yes, they count as hobbies). This will keep you energized and motivated enough to keep at your work. So basically, for the sake of your PhD, you need to have some occasional time away from it.
Read. Keeping up with your field is an important part of being a researcher. You don’t want to waste time working on a question that’s already been answered or developing a method that already exists. So read papers. Within your exact line of research read all kinds of papers, old and new, and especially the ones that your adviser constantly references. More broadly, know the seminal works in your field and keep up to date with current trends. Subscribe to email or RSS feeds from the main journals and actually look at them. Try to read papers completely outside your field if you think there is some aspect to them that might be relevant to you, or if you’re just interested. Basically, you should get really good at being able to read any paper, assessing its merit, and understanding its importance to your work and/or the field as a whole.
Of course, all this reading can conflict with your above-mentioned attempts at time management. So another important skill for grad students is to know when to stop. You can’t know every experiment that’s ever been done, and eventually you need to start doing your own. Pick your papers wisely, get good at reading them quickly, and learn to accept when you’ve learned enough. Attending talks can be a good way of getting a lot of information fed to you in about an hour, but they should also be chosen wisely. Since you can’t skim a talk to get to the good parts, you should avoid those with only limited potential for keeping your interest. And if you do take the time to attend them, make sure to stay attentive and awake (not that I’ve ever had any kind of problem with that whatsoever).
Write. The main output of any research is a journal article. If you can’t write about your work then you haven’t finished the job. And if you can’t write a thesis then you haven’t finished your PhD. So you need to get good at writing. And the only way to do that is practice, practice, practice. Take any opportunity to write. One great idea is to periodically create a writeup on your project as you’re working on it. Not only does this give you practice, but it keeps you focused on how what you’re doing at that time fits into your overall narrative, and lightens the work load at the end of your project when you’re looking to submit. A key component to good writing in science is, of course, to convey complicated concepts in as simple a way as possible. And the best way to practice that is to try explaining what you do to someone completely outside the field (family usually works well for this). These kinds of exercises don’t just help your writing, they help your science. As Einstein said, “If you can’t explain it simply, you don’t understand it well enough.”
Think. Possibly one of the simplest yet profoundest pieces of advice for a young researcher. It can be tempting, especially as a graduate student with a weekly meeting with an adviser looming, to simply churn out whatever kind of results you can possibly attain, without giving much thought, for example, to why you’re doing a particular kind of analysis or what the results really mean. This kind of rote work rarely leads to meaningful findings. So, allow yourself time devoted to just really thinking about your work. No multi-tasking, just quiet thought. Think about what you’re doing and why and how it fits in with your knowledge of the rest of the field. Brainstorm potential solutions to the problem you’re working on, and ways of testing each of them. The ability to entertain multiple possibilities at once and coping with ambiguity are important traits in successful researchers. Engaging in deep thought (and writing down those thoughts) helps develop these and other meaningful skills in ways that superficial work never could.
Ask Questions. Ask questions at talks, ask questions in class, ask questions to your adviser, ask questions during journal club, ask questions to other grad students. Just, for the love of whatever you think is holy, ask questions whenever you have them. There is a common fear, especially amongst students, that the question you want to ask is going to betray your ignorance. The answer, you assume, is so obvious to everyone else in the room that your very asking of it is going to get you kicked right out of graduate school. The odds of this happening, however, are very small. The odds of someone else in the room having a similar question that they are equally afraid of asking is probably much higher. So be the hero and ask it. There is no way to get answers otherwise. And if graduate school isn’t the time that you get to ask unlimited (possibly stupid) questions, then when is? For younger grad students its especially beneficial to get information from older students that you can’t get elsewhere: advice on classes, advisers, administrative hurdles, etc. So worry less about looking smart, and actually get smart by asking as many questions as you need.
Network. Yes, that terrible n-word. To most scientists “networking” brings up images of people in suits exchanging business cards over power lunches. To us, there is just something phony about it. But the fact is that collaborations are a huge part of science, and you can’t have them without the ability to branch out to other people in your field. It’s easy enough to get to know people you work with regularly, but it’s also important to meet people with similar interests outside of your institution. Conferences are a great opportunity for that. The key is to follow through concretely. Get the email address of the person you had a really engaging conversation with at SfN. Follow the work of the labs you like and email authors when you have a question about their paper. As difficult as it can be for a typically solitary scientist, socialization and self-promotion are necessary. You want to get your name out there for when opportunities in your field open up, and you want to know who to contact when you need someone with a specific set of skills. Take your natural desire to talk about work that interests you and push it just a little bit further into the realm of “networking.”
Overall, it’s important to remember that you are not a PhD-producing robot. You are a person doing a PhD, and so the habits you develop need to be sustainable and keep you interested while still allowing you to achieve your goals in a timely manner. You will need to work hard, since at this level intelligence is a given. But if you’ve gotten to the point of working on a PhD, the research questions themselves should drive you. As Arnold Toynbee said, “The supreme accomplishment is to blur the line between work and play.”
